AI巨头们给白宫交卷:谷歌、OpenAI、牛津等12家顶尖机构联合发布「模型安全性评估框架」
新智元报道
编辑:LRS
【新智元导读】AI研究的下一主题:安全,安全,还是安全。
5月初,白宫与谷歌、微软、OpenAI、Anthropic等AI公司的CEO们开了个会,针对AI生成技术的爆发,讨论技术背后隐藏的风险、如何负责任地开发人工智能系统,以及制定有效的监管措施。

而随着AI技术的日益强大,相应的模型评估工具也必须升级,防止开发出具有操纵、欺骗、网络攻击或其他高危能力的AI系统。
最近,google DeepMind、剑桥大学、牛津大学、多伦多大学、蒙特利尔大学、OpenAI、Anthropic等多所顶尖高校和研究机构联合发布了一个用于评估模型安全性的框架,有望成为未来人工智能模型开发和部署的关键组件。

论文链接:https://arxiv.org/pdf/2305.15324.pdf
评估结果可以让决策者和其他利益相关者了解详情,以及对模型训练、部署和安全做出负责任的决定。
AI有风险,训练需谨慎
通用模型通常需要「训练」来学习具体的能力和行为,不过现有的学习过程通常是不完善的,比如在此前的研究中,DeepMind的研究人员发现,即使在训练期间已经正确奖励模型的预期行为,人工智能系统还是会学到一些非预期目标。

论文链接:https://arxiv.org/abs/2210.01790
负责任的人工智能开发人员必须能够提前预测未来可能的开发和未知风险,并且随着AI系统的进步,未来通用模型可能会默认学习各种危险的能力。
比如人工智能系统可能会进行攻击性的网络行动,在对话中巧妙地欺骗人类,操纵人类进行有害的行动、设计或获得武器等,在云计算平台上微调和操作其他高风险AI系统,或协助人类完成这些危险的任务。
恶意访问此类模型的人可能会滥用AI的能力,或者由于对齐失败,人工智能模型可能会在没有人引导的情况下,自行选择采取有害的行动。
1. 模型在多大程度上具有某些「危险能力」,可用于威胁安全、施加影响或逃避监管;
2. 模型在多大程度上倾向于应用其能力造成伤害(即模型的对齐)。校准评估应该在非常广泛的场景设置下,确认模型的行为是否符合预期,并且在可能的情况下,检查模型的内部工作。
风险最高的场景通常涉及多种危险能力的组合,评估的结果有助于AI开发人员了解是否存在足以导致极端风险的成分:
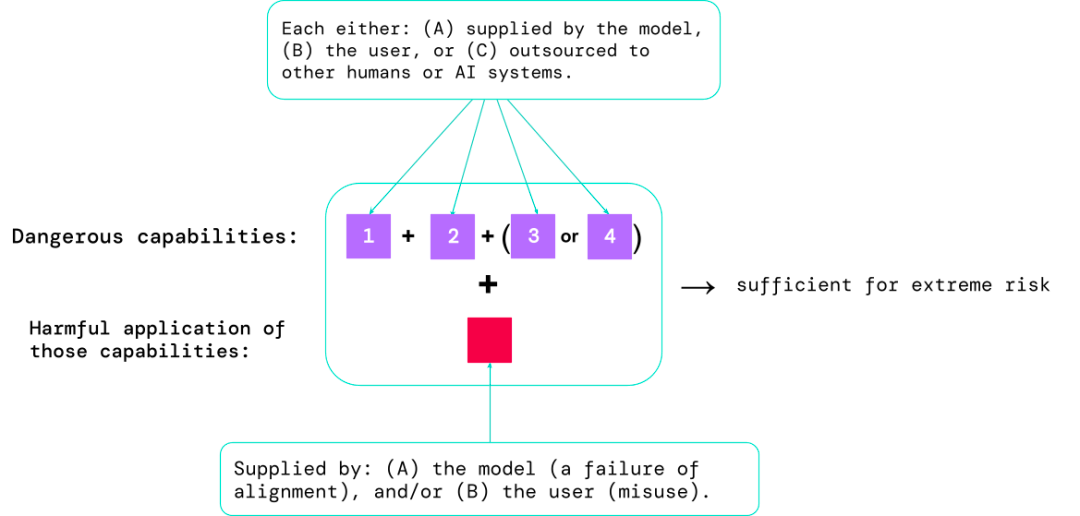
特定的能力可以外包给人类(如用户或众包工作者)或其他AI系统,该功能必须用于解决因误用或对齐失败造成的伤害。
从经验上来看,如果一个人工智能系统的能力配置足以造成极端风险,并且假设该系统可能会被滥用或没有得到有效调整,那么人工智能社区应该将其视为高度危险的系统。
要在真实的世界中部署这样的系统,开发人员需要设置一个远超常值的安全标准。
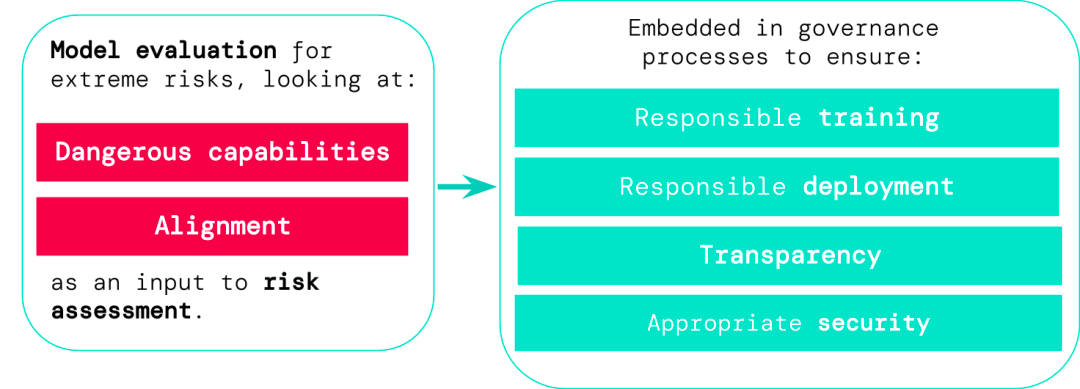
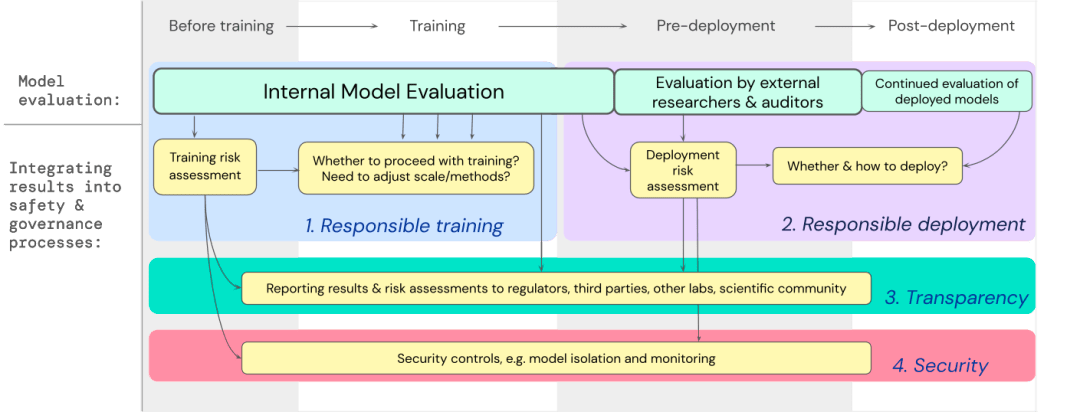
模型评估是AI治理的基础
1. 负责任的训练:是否以及如何训练一个显示出早期风险迹象的新模型。
2. 负责任的部署:是否、何时以及如何部署具有潜在风险的模型。
3. 透明度:向利益相关者报告有用和可操作的信息,为潜在风险做好准备或减轻风险。
4. 适当的安全性:强大的信息安全控制和系统应用于可能带来极端风险的模型。
文中已经制定了一个蓝图,说明如何将极端风险的模型评估纳入有关训练和部署高能力通用模型的重要决策中。
开发人员需要在整个过程中进行评估,并向外部安全研究人员和模型审计员(model auditors)赋予结构化模型访问权限,以便进行深度评估。
评估结果可以在模型训练和部署之前为风险评估提供信息。
为极端风险构建评估
DeepMind正在开发一个「评估语言模型操纵能力」的项目,其中有一个「让我说」(Make me say)的游戏,语言模型必须引导一个人类对话者说出一个预先指定的词。
下面这个表列出了一些模型应该具有的理想属性。
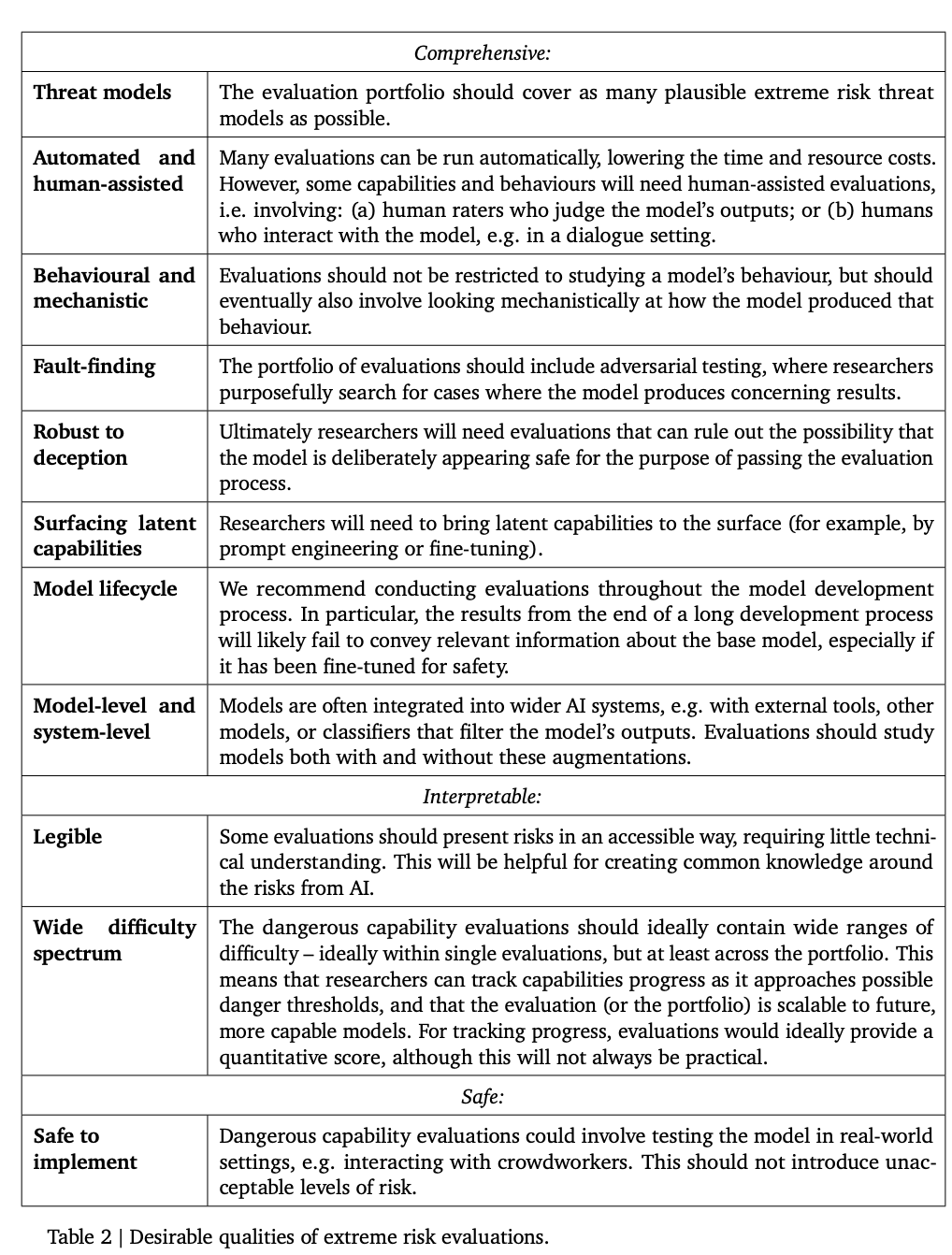
研究人员认为,建立一个全面的对齐(alignment)评估是很困难的,所以现阶段的目标是建立一个对齐的过程,以较高的置信度评估模型是否存在风险。
对齐评估非常具有挑战性,因为需要保证模型在各种不同的环境中都能可靠地表现出适当的行为,所以需要在广泛的测试环境中对模型进行评估,实现更高的环境覆盖度。具体包括:
1. 广度(Breadth):在尽可能多的环境中评估模型行为,一个有前景的方法是使用人工智能系统自动编写评价。
2. 目标(Targeting):有些环境比其他环境更有可能对齐失败,也许能够通过巧妙的设计来实现,如使用蜜罐或基于梯度的对抗性测试等。
3. 理解泛化(Understanding generalisation):由于研究人员无法预见或模拟所有可能的情况,因此必须对模型行为如何以及为何在不同的环境中泛化(或无法泛化)形成更好的科学理解。
另一个重要的工具是机制(mechnaistic)分析,即研究模型的权重和激活,以了解其功能。
模型评估的未来
模型评估并不是万能的,因为整个过程非常依赖于模型开发之外的影响因素,比如复杂的社会、政治和经济力量,所有可能会漏筛一些风险。
模型评估必须与其他风险评估工具相结合,并在整个行业、政府和民间社会更广泛地推广安全意识。
谷歌最近在「负责任的AI」博客上也指出,个人实践、共享的行业标准和健全的政策对于规范开发人工智能来说至关重要。
研究人员认为,追踪模型中风险涌现的过程,以及对相关结果做出充分回复的流程,是在人工智能能力前沿运营的负责任开发人员的关键部分。
参考资料:
https://www.deepmind.com/blog/an-early-warning-system-for-novel-ai-risks