Redis延迟问题全面排障指南
redis延迟问题全面排障指南
作者:kevine
前言
在 Redis 的实际使用过程中,我们经常会面对以下的场景:
- 在 Redis 上执行同样的命令,为什么有时响应很快,有时却很慢;
- 为什么 Redis 执行 GET、SET、DEL 命令耗时也很久;
- 为什么我的 Redis 突然慢了一波,之后又恢复正常了;
- 为什么我的 Redis 稳定运行了很久,突然从某个时间点开始变慢了。
这时我们还是需要一个全面的排障流程,不能无厘头地进行优化;全面的排障流程可以帮助我们找到真正的根因和性能瓶颈,以及实施正确高效的优化方案。
这篇文章我们就从可能导致 Redis 延迟的方方面面开始,逐步深入排障深水区,以提供一个「全面」的 Redis 延迟问题排查思路。
需要了解的词
- Copy On WriteCOW是一种建立在虚拟内存重映射技术之上的技术,因此它需要 MMU的硬件支持, MMU会记录当前哪些内存页被标记成只读,当有进程尝试往这些内存页中写数据的时候, MMU就会抛一个异常给操作系统内核,内核处理该异常时为该进程分配一份物理内存并复制数据到此内存地址,重新向 MMU发出执行该进程的写操作。
- 内存碎片操作系统负责为每个进程分配物理内存,而操作系统中的虚拟内存管理器保管着由内存分配器分配的实际内存映射 如果我们的应用程序需求1GB大小的内存,内存分配器将首先尝试找到一个 连续的内存段来存储数据;如果找不到连续的段,则分配器必须将进程的 数据分成多个段,从而导致内存开销增加。
- SWAP顾名思义,当某进程向 OS 请求内存发现不足时,OS 会把内存中暂时不用的数据交换出去,放在SWAP分区中,这个过程称为 SWAP OUT。 当某进程又需要这些数据且 OS 发现还有空闲物理内存时,又会把 SWAP分区中的数据交换回物理内存中,这个过程称为 SWAP IN,详情可参考这篇文章。
- redis 监控指标合理完善的监控指标无疑能大大助力我们的排障,本篇文章中提到了很多的 redis 监控指标,详情可以参考这篇文章: redis 监控指标
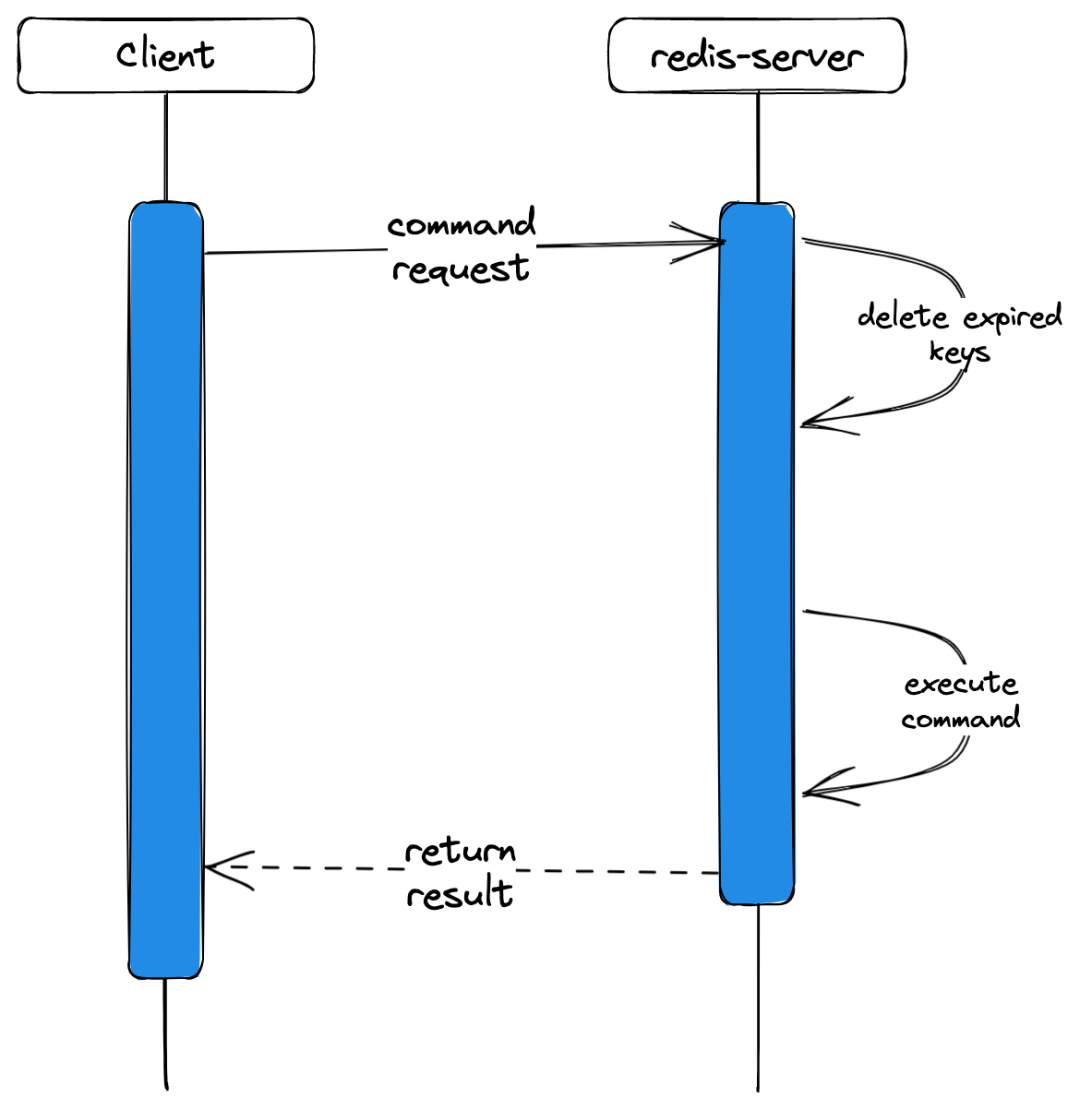
当我们发现从我们的业务服务发起请求到接收到Redis的回包这条链路慢时,我们需要先排除其它的一些无关 Redis自身的原因,如:
- 业务自身准备请求耗时过长;
- 业务服务器到 Redis服务器之间的网络存在问题,例如网络线路质量不佳,网络数据包在传输时存在延迟、丢包等情况; 网络和通信导致的固有延迟:客户端使用 TCP/IP连接或 Unix域连接连接到 Redis,在 1 Gbit/s网络下的延迟约为 200 us,而 Unix域Socket的延迟甚至可低至 30 us,这实际上取决于网络和系统硬件;在网络通信的基础之上,操作系统还会增加了一些额外的延迟(如 线程调度、CPU缓存、NUMA等);并且在虚拟环境中,系统引起的延迟比在物理机上也要高得多的结果就是,即使 Redis 在亚微秒的时间级别上能处理大多数命令,网络和系统相关的延迟仍然是不可避免的。
- Redis实例所在的机器带宽不足 / Docker网桥性能问题等。
排障事大,但咱也不能冤枉了Redis;首先我们还是应该把其它因素都排除完了,再把焦点关注在业务服务到 Redis这条链路上。如以下的火焰图就可以很肯定的说问题出现在 Redis 上了:
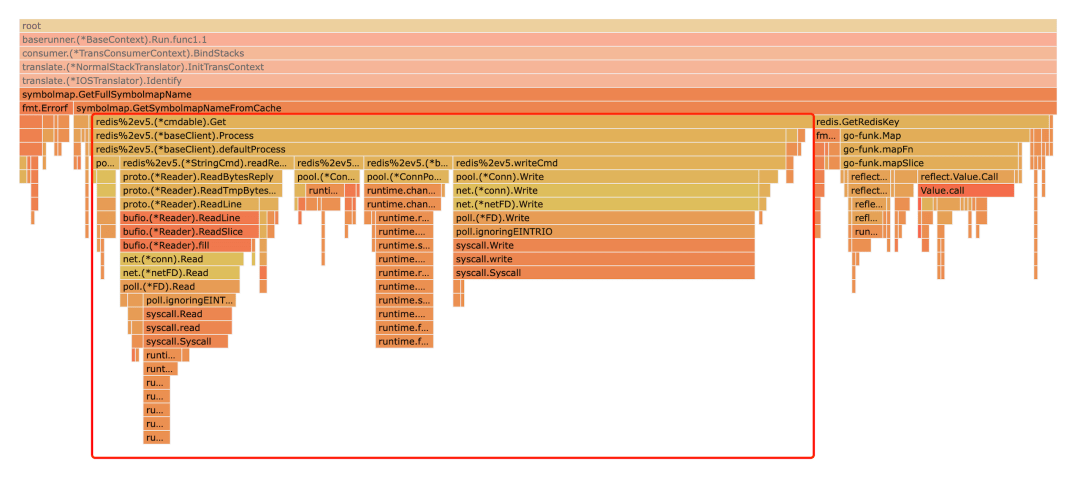
在排除无关因素后,如何确认 Redis 是否真的变慢了?
测试流程
排除无关因素后,我们可以按照以下基本步骤来判断某一 Redis 实例是否变慢了:
- 监控并记录一个相对正常的 Redis 实例(相对低负载、key 存储结构简单合理、连接数未满)的相关指标;
- 找到认为表现不符合预期的 Redis 实例(如使用该实例后业务接口明显变慢),在相同配置的服务器上监控并记录这个实例的相关指标;
- 若表现不符合预期的 Redis 实例的相关指标明显达不到正常 Redis 实例的标准(延迟两倍以上、OPS仅为正常实例的 1/3、 内存碎片率较高等),即可认为这个 Redis 实例的指标未达到预期。
确认是 Redis 实例的某些指标未达到预期后,我们就可以开始逐步分析拆解可能导致 Redis 表现不佳的因素,并确认优化方案了。
快速清单
I've little time, give me the checklist
在线上发生故障时,我们都没有那么多时间去深究原因,所以在深入到排障的深水区前,我们可以先从最影响最大的一些问题开始检查,这里是一份「会对redis基本运行造成严重影响的问题」的 checklist:
- 确保没有运行阻塞服务器的缓慢命令;使用 Redis 的耗时命令记录功能来检查这一点;
- 对于 EC2 用户,请确保使用基于HVM的现代 EC2 实例,如 m3.dium等,否则, fork系统调用带来的延迟太大了;
- 禁用透明内存大页。使用echo never > /sys/kernel/mm/transparent_hugepage/enabled来禁用它们,然后重新启动 Redis 进程;
- 如果使用的是虚拟机,则可能存在与 Redis 本身无关的固有延迟;使用redis-cli --intrinsic-latency 100检查延迟,确认该延迟是否符合预期(注意:您需要在服务器上而不是在客户机上运行此命令);
- 启用并使用 Redis 的延迟监控功能,更好的监控 Redis 实例中的延迟事件和原因。
如果使用我们的快速清单并不能解决实际的延迟问题,我们就得深入 redis 性能排障的深水区,多方面逐步深究其中的具体原因了。
使用复杂度过高的命令 / 「大型」命令
要找到这样的命令执行记录,需要使用 Redis 提供的耗时命令统计的功能,查看 Redis 耗时命令之前,我们需要先在redis.conf中设置耗时命令的阈值;如:设置耗时命令的阈值为 5ms,保留近 500 条耗时命令记录:
# The following time is expressed in microseconds, so 1000000 is equivalent# to one second. Note that a negative number disables the slow log, while# a value of zero forces the logging of every command.slowlog-log-slower-than 10000# There is no limit to this length. Just be aware that it will consume memory.# You can reclAIm memory used by the slow log with SLOWLOG RESET.slowlog-max-len 128
或是直接在redis-cli中使用 CONFIG命令配置:
# 命令执行耗时超过 5 毫秒,记录耗时命令CONFIG SET slowlog-log-slower-than 5000# 只保留最近 500 条耗时命令CONFIG SET slowlog-max-len 500
通过查看耗时命令记录,我们就可以知道在什么时间点,执行了哪些比较耗时的命令。
如果应用程序执行的 Redis 命令有以下特点,那么有可能会导致操作延迟变大:
- 经常使用 O(N) 以上复杂度的命令,例如 SORT, SUNION, ZUNIONSTORE 等聚合类命令
- 使用 O(N) 复杂度的命令,但 N 的值非常大
第一种情况导致变慢的原因是 Redis 在操作内存数据时,时间复杂度过高,要花费更多的 CPU 资源。
第二种情况导致变慢的原因是 处理「大型」redis 命令(大请求包体 / 大返回包体的 redis 请求),对于这样的命令来说,虽然其只有两次内核态与用户态的上下文切换,但由于 redis 是单线程处理回调事件的,所以后续请求很有可能被这一个大型请求阻塞,这时可能需要考虑业务请求拆解尽量分批执行,以保证 redis 服务的稳定性。
Bigkey
bigkey 一般指包含大量数据或大量成员和列表的 key,如下所示就是一些典型的 bigkey(根据 Redis 的实际用例和业务场景,bigkey 的定义可能会有所不同):
- value 大小为 5 MB(数据太大)的 String
- 包含 20000 个元素的List(列表中的元素数量过多)
- 有 10000 个成员的ZSET密钥(成员数量过多)
- 一个大小为 100 MB 的Hash key,即便只包含 1000 个成员(key 太大)
在上一节的耗时命令查询中,如果我们发现榜首并不是复杂度过高的命令,而是 SET / DEL 等简单命令,这很有可能就是 redis 实例中存在 bigkey导致的。
bigkey 会导致包括但不限于以下的问题:
- Redis 的内存使用量不断增长,最终导致实例 OOM,或者因为达到最大内存限制而导致写入被阻塞和重要 key 被驱逐;
- 访问偏差导致的资源倾斜,bigkey的存在可能会导致某个 Redis 实例达到性能瓶颈,从而导致整个集群也达到性能瓶颈;在这种情况下,Redis 集群中一个节点的内存使用量通常会因为对 bigkey的访问需求而远远超过其他节点,而 Redis 集群中数据迁移时有一个最小粒度,这意味着该节点上的 bigkey 占用的内存无法进行 balance;
- 由于将 bigkey 请求从 socket 读取到 Redis 占用了几乎所有带宽,Redis 的其它请求都会受到影响;
- 删除 BigKey 时,由于主库长时间阻塞(释放 bigkey 占用的内存)导致同步中断或主从切换。
如何定位 bigkey
- 使用 redis-cli 提供的—-bigkeys参数 redis-cli提供了扫描 bigkey 的 option —-bigkeys,执行以下命令就可以扫描 redis 实例中 bigkey 的分布情况,以 key 类型维度输出结果: $ redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 0.01
[00.00%] Biggest string found so far
...
[98.23%] Biggest string found so far
-------- summary -------
Sampled 829675 keys inthe keyspace!
Total key length inbytes is 10059825 (avg len 12.13)
Biggest string found 'key:291880'has 10 bytes
Biggest list found 'mylist:004'has 40 items
Biggest setfound 'myset:2386'has 38 members
Biggest hashfound 'myhash:3574'has 37 fields
Biggest zset found 'myzset:2704'has 42 members
36313 strings with 363130 bytes (04.38% of keys, avg size 10.00)
787393 lists with 896540 items (94.90% of keys, avg size 1.14)
1994 sets with 40052 members (00.24% of keys, avg size 20.09)
1990 hashs with 39632 fields (00.24% of keys, avg size 19.92)
1985 zsets with 39750 members (00.24% of keys, avg size 20.03)
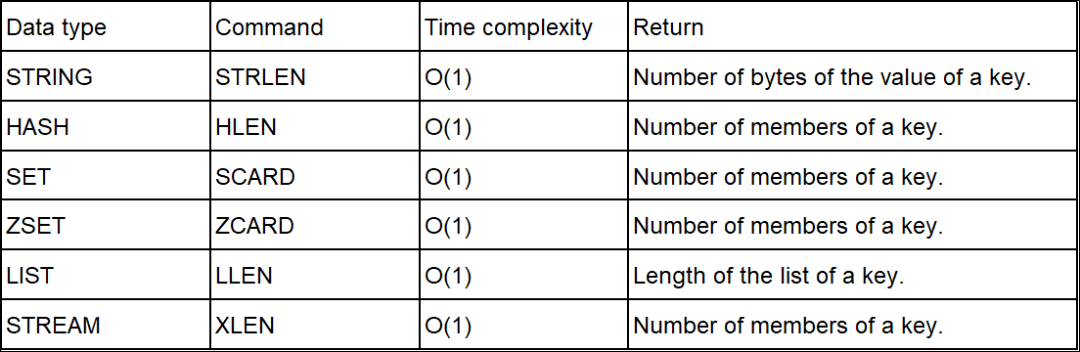
从输出结果我们可以很清晰地看到,每种数据类型所占用的最大内存 / 拥有最多元素的 key 是哪一个,以及每种数据类型在整个实例中的占比和平均大小 / 元素数量。 bigkey 扫描实际上是 Redis 执行了 SCAN 命令,遍历整个实例中所有的 key,然后针对 key 的类型,分别执行 STRLEN, LLEN, HLEN, SCARD和ZCARD命令,来获取 String 类型的长度,容器类型(List, Hash, Set, ZSet)的元素个数。 ⚠️NOTICE: 当执行 bigkey 扫描时,要注意 2 个问题:以下是 bigkey 扫描实际用到的命令的时间复杂度:
- 对线上实例进行 bigkey 扫描时,Redis 的 OPS 会突增,为了降低扫描过程中对 Redis 的影响,最好控制一下扫描的频率,指定 -i参数即可,它表示扫描过程中每次扫描后休息的时间间隔(秒);
- 扫描结果中,对于容器类型(List, Hash, Set, ZSet)的 key,只能扫描出元素最多的 key;但一个 key 的元素多,不一定表示内存占用也多,我们还需要根据业务情况,进一步评估内存占用情况。
- 使用开源的 redis-rdb-tools通过 redis-rdb-Tools,我们可以根据自己的标准准确分析 Redis 实例中所有密钥的实际内存使用情况,同时它还可以避免中断在线服务,分析完成后,您可以获得简洁、易于理解的报告。 redis-rdb-Tools对 rdb文件的分析是离线的,对在线的 redis 服务没有影响;这无疑是它对比第一种方案最大的优势,但也正是因为是离线分析,其分析结果的实时性可能达不到某些场景下的标准,对大型 rdb文件的分析可能需要较长的时间。
针对 bigkey 问题的优化措施:
- 上游业务应避免在不合适的场景写入 bigkey(夸张一点:用String存储大型 binary file),如必须使用,可以考虑进行 大key拆分,如:对于 string 类型的 Bigkey,可以考虑拆分成多个 key-value;对于 hash 或者 list 类型,可以考虑拆分成多个 hash 或者 list。
- 定期清理HASH key中的无效数据(使用 HSCAN和 HDEL),避免 HASH key中的成员持续增加带来的 bigkey 问题。
- Redis ≥ 4.0中,用 UNLINK命令替代 DEL,此命令可以把释放 key 内存的操作,放到后台线程中去执行,从而降低对 Redis 的影响。
- Redis ≥ 6.0中,可以开启 lazy-free 机制(lazyfree-lazy-user-del = yes),在执行 DEL 命令时,释放内存也会放到后台线程中执行。
- 针对消息队列 / 生产消费场景的 List, Set 等,设置过期时间或实现定期清理任务,并配置相关监控以及时处理突发情况(如线上流量暴增,下有服务无法消费等产生的消费积压)。
即便我们有一系列的解决方案,我们也要尽量避免在实例中存入 bigkey。这是因为 bigkey 在很多场景下,依旧会产生性能问题;例如,bigkey 在分片集群模式下,对于数据的迁移也会有性能影响;以及资源倾斜、数据过期、数据淘汰、透明大页等,都会受到 bigkey 的影响。
Hotkey
在讨论 bigkey 时,我们也经常谈到 hotkey ,当访问某个密钥的工作量明显高于其他密钥时,我们可以称之为 hotkey;以下就是一些 hotkey 的例子:
- 在一个 QPS 10w 的 Redis 实例中,只有一个 key 的 QPS 达到了 7000 次;
- 拥有数千个成员、总大小为 1MB 的哈希键每秒会收到大量的 HGETALL 请求(在这种情况下,我们将其称为热键,因为访问一个键比访问其他键消耗的带宽要大得多);
- 拥有数万个 member 的 ZSET 每秒处理大量的 ZRANGE 请求(cpu时间明显高于用于其他 key 请求的 cpu时间。同样,我们可以说这种消耗大量 CPU 的 Key 就是 HotKey)。
hotkey 通常会带来以下的问题:
- hotkey 会导致较高的 CPU 负载,并影响其它请求的处理;
- 资源倾斜,对 hotkey 的请求会集中在个别 Redis 节点/机器上,而不是shard到不同的 Redis 节点上,导致 内存/CPU 负载集中在这个别的节点上,Redis 集群利用率不能达到预期;
- hotkey 上的流量可能在流量高峰时突然飙升,导致 redis CPU 满载甚至缓存服务崩溃,在缓存场景下导致缓存雪崩,大量的请求会直接命中其它较慢的数据源,最终导致业务不可用等不可接受的后果。
如何定位 hotkey:
- 使用redis-cli提供的 —hotkeys参数 Redis 从 4.0版本开始在 redis-cli中提供 hotkey 参数,以方便实例粒度的 hotkey 分析;它可以返回所有 key 被访问的次数,但需要先将 maxmemory policy设置为 allkey-LFU。# Scanning the entire keyspace to find hot keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
Error: ERR An LFU maxmemory policy is not selected, access frequency not tracked. Please note that when switching between policies at runtime LRU and LFU data will take some time to adjust.
- 使用monitor命令 Redis 的 monitor命令可以实时输出 Redis 接收到的所有请求,包括 访问时间、客户端 IP、命令和 key;我们可以短时间执行 monitor 命令,并将输出重定向到文件;结束后,可以通过对文件中的请求进行分类和分析来找到这段时间的 hotkey。 monitor命令会消耗大量 CPU、内存和网络资源;因此,对于本身就负载较大的 Redis 实例来说, monitor命令可能会让性能问题进一步恶化;同时,这种异步采集分析方案的时效性较差,分析的准确性依赖于 monitor命令的执行时长;因此,在大多数无法长时间执行该命令的在线场景中,结果的准确性并不好。
- 上游服务针对 redis 请求进行监控 所有的 redis 请求都来自于上游服务,上游服务可以在上报时进行相关的指标监控、汇总及分析,以定位 hotkey ;但这样的方式需要上游服务支持,并不独立。
针对 hotkey 问题的优化方案:
1.使用pipeline
在一些非实时的 bigkey 请求场景下,我们可以使用 pipeline来大幅度降低 Redis 实例的 CPU 负载。
首先我们要知道,Redis 核心的工作负荷是一个单线程在处理,这里指的是——网络 IO和命令执行是由一个线程来完成的;而 Redis 6.0 中引入了多线程,在 Redis 6.0之前,从网络 IO 处理到实际的读写命令处理都是由单个线程完成的,但随着网络硬件的性能提升,Redis 的性能瓶颈有可能会出现在网络 IO 的处理上,也就是说单个主线程处理网络请求的速度跟不上底层网络硬件的速度。针对此问题,Redis 采用多个 IO 线程来处理网络请求,提高网络请求处理的并行度,但多 IO 线程只用于处理网络请求,对于命令处理,Redis 仍然使用单线程处理。
而 Redis 6.0 以前的单线程网络 IO 模型的处理具体的负载在哪里呢?虽然 Redis 利用epoll机制实现 IO 多路复用(即使用 epoll监听各类事件,通过事件回调函数进行事件处理),但 I/O 这一步骤是无法避免且始终由单线程串行处理的,且涉及用户态/内核态的切换,即:
- 从socket中读取请求数据,会从内核态将数据拷贝到用户态 ( read调用)
- 将数据回写到socket,会将数据从用户态拷贝到内核态 ( write调用)
高频简单命令请求下,用户态/内核态的切换带来的开销被更加放大,最终会导致redis-servercpu满载 → redis-serverOPS不及预期 → 上游服务海量请求超时 → 最终造成类似 缓存穿透的结果,这时我们就可以使用 pipeline来处理这样的场景了:redis pipeline。
众所周知,redis pipeline可以让 redis-server一次接收一组指令(在内核态中存入输入缓冲区,收到客户端的 Exec指令再调用 read syscall)后再执行,减少 I/O(即 accept -> read -> write)次数,在 高频可聚合命令的场景下使用 pipeline可以大大减少 socket I/O带来的 内核态与用户态之间的上下文切换开销。
下面我们进行跑一组基于golang redis客户端的简单高频命令的 Benchmark测试(不使用 pipeline和使用 pipeline对比),同时使用perf对 Redis 4 实例监控上下文切换次数:
- Set without Pipeline(redis 4.0.14)perf stat-p 15537 -e context-switches -a sleep 10
Performance counter stats forprocess id '15537':
96,301 context-switches
10.001575750 seconds time elapsed
- Set using Pipeline(redis 4.0.14)perf stat-p 15537 -e context-switches -a sleep 10
Performance counter stats forprocess id '15537':
17 context-switches
10.001722488 seconds time elapsed
可以看到在不使用pipeline执行高频简单命令时产生了大量的上下文切换,这无疑会占用大量的 cpu时间。
另一方面,pipeline虽然好用,但是每次 pipeline组装的命令个数不能没有节制,否则一次组装 pipeline数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的 pipeline拆分成多次较小的 pipeline来完成,比如可以将 pipeline的总发送大小控制在内核输入输出缓冲区大小之内(内核的输入输出缓冲区大小一般是 4K-8K,在不同操作系统中有所差异,可配置修改),同时控制在 单个 TCP 报文最大值 1460 字节之内。
最大传输单元(MTU — Maximum Transmission Unit)在以太网中的最大值是1500 字节,扣减 20 个字节的 IP头和 20 个字节的 TCP头,即 1460 字节
2.MemCache当 hotkey 本身可预估,且总大小可控时,我们可以考虑使用MemCache直接存储:
- 省去了 Redis 接入
- 直接的内存读取,保证高性能
- 摆脱带宽限制
但同时它也带来了新的问题:
- 在像k8s这样的高可用多实例架构下,多 pod间的同步以及和原始数据库的同步是一个大问题,很有可能导致 脏读
- 同样是在多实例的情况下,会带来很多的内存浪费。
同时 MemCache 相比于 Redis 也少了很多 feature ,可能不能满足业务需求
FeatureRedisMemCache原生支持不同的数据结构✅❌原生支持持久化✅❌横向扩展(replication)✅❌聚合操作✅❌支持高并发✅✅
3.Redis 读写分离
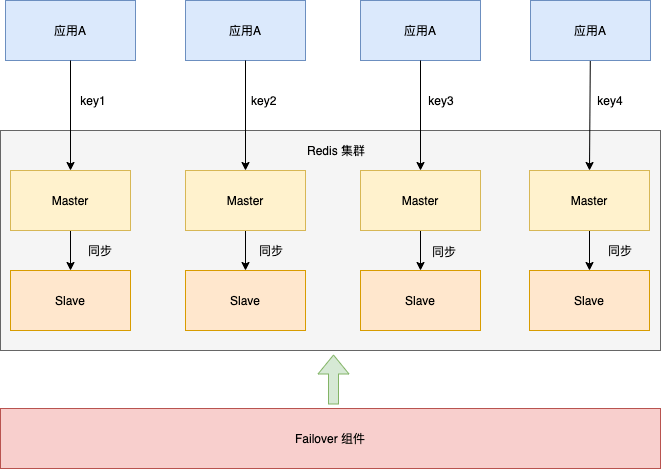
当对 hotkey 的请求仅仅集中在读上时,我们可以考虑读写分离的 Redis 集群方案(很多公有云厂商都有提供),针对 hotkey 的读请求,新增read-only replica来承担读流量,原 replica作为热备不提供服务,如下图所示(链式复制架构)。

这里我们不展开讲读写分离的其它优势,仅针对读多写少的业务场景来说,使用读写分离的 Redis 提供了更多的选择,业务可以根据场景选择最适合的规格,充分利用每一个read-only replica的资源,且读写分离架构还有比较好的横向扩容能力、客户端友好等优势。
规格QPS带宽1 master8-10 万读写10-48 MB1 master + 1 read-only replica10 万写 + 10 万读20-64 MB1 master + 3 read-only replica10 万写 + 30 万读40-128 MBn _ master + m _ read-only replican _ 100,000 write + m _ 100,000 read10(m+n) MB - 32(m+n) MB
当然我们也不能忽略读写分离架构的缺点,在有大量写请求的场景中,读写分离架构将不可避免地产生延迟,这很有可能造成脏读,所以读写分离架构不适用于读写负载都较高以及实时性要求较高的场景。
Key 集中过期
当 Redis 实例表现出的现象是:周期性地在一个小的时间段出现一波延迟高峰时,我们就需要 check 一下是否有大批量的 key 集中过期;那么为什么 key 集中过期会导致 Redis 延迟变大呢?
我们首先来了解一下 Redis 的过期策略是怎样的,Redis 处理过期 key 的方式有两种——被动方式和主动方式。
被动方式
key过期的时候不删除,每次从 Redis 获取 key时检查是否过期,若过期,则删除,返回 null。
优点:删除操作只发生在从数据库取出 key 的时候发生,而且只删除当前key,所以对 CPU 时间的占用是比较少的。
缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,此时的无效缓存是永久暂用在内存中的,那么可能发生内存泄露(无效 key占用了大量的内存)。
主动方式
Redis 每100ms执行以下步骤:
- 抽样检查附加了TTL的 20 个随机 key(环境变量 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP,默认为 20);
- 删除抽样中所有过期的key;
- 如果超过25%的 key过期,重复步骤 1。
优点:通过限制删除操作的时长和频率,来限制删除操作对 CPU 时间的占用;同时解决被动方式中无效 key存留的问题。
缺点: 仍然可能有最高达到25%的无效key存留;在 CPU时间友好方面,不如 被动方式,主动方式会 block住主线程。
难点: 需要合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除,这要根据服务器运行情况和实际需求来决定)。
如果 Redis 实例配置为上面的主动方式的,当 Redis 中的 key 集中过期时,Redis 需要处理大量的过期 key;这无疑会增加 Redis 的 CPU 负载和内存使用,可能会使 Redis 变慢,特别当 Redis 实例中存在 bigkey 时,这个耗时会更久;而且这个耗时不会被记录在slow log中:
解决方案:
为了避免这种情况,可以考虑以下几种方法:
- 尽量避免 key 集中过期,如果需要批量插入 key(如批量插入一批设置了同样ExpireAt的 key),可以通过额外的小量随机过期时间来打散 key 的过期时间;
- 在 Redis 4.0 以上的版本中提供了 lazy-free 选项,当删除过期 key 时,把释放内存的操作放到后台线程中执行,避免阻塞主线程。
从监控的角度出发,我们还需要建立对expired_keys的实时监控和突增告警,以及时发出告警帮助我们定位到业务中的相关问题。
触及 maxmemory
当我们的 Redis 实例达到了设置的内存上限时,我们也会很明显地感知到 Redis 延迟增大。
究其原因,当 Redis 达到 maxmemory 后,如果继续往 Redis 中写入数据,Redis 将会触发内存淘汰策略来清理一些数据以腾出内存空间,这个过程需要耗费一定的 CPU 和内存资源,如果淘汰过程中产生了大量的 Swap 交换或者内存回收,将会导致 Redis 变慢,甚至可能导致 Redis 崩溃。
常见的驱逐策略有以下几种:
- noeviction: 不删除策略,达到最大内存限制时,如果需要更多内存,直接返回错误信息;大多数写命令都会导致占用更多的内存(有极少数会例外, 如 DEL );
- allkeys-lru: 所有 key 通用; 优先删除最长时间未被使用(less recently used ,LRU) 的 key;
- volatile-lru: 只限于设置了 expire 的部分; 优先删除最长时间未被使用(less recently used ,LRU) 的 key;
- allkeys-random: 所有 key 通用; 随机删除一部分 key;
- volatile-random: 只限于设置了 expire 的部分; 随机删除一部分 key;
- volatile-ttl: 只限于设置了 expire 的部分; 优先删除剩余时间(time to live,TTL) 短的 key;
- volatile-lfu: added in Redis 4, 从设置了 expire 的 key 中删除使用频率最低的 key;
- allkeys-lfu: added in Redis 4, 从所有 key 中删除使用频率最低的 key。
最常用的驱逐策略是allkeys-lru / volatile-lru。
⚠️ 需要注意的是:Redis 的淘汰数据的逻辑与删除过期 key 的一样,也是在命令真正执行之前执行的,也就是说它也会增加我们操作 Redis 的延迟,并且写 OPS 越高,延迟也会越明显。
另外,如果 Redis 实例中还存储了 bigkey,那么在淘汰删除 bigkey 释放内存时,也会耗时比较久。
解决方案:
为了避免 Redis 达到 maxmemory 后变慢,可以考虑以下几种解决方案:
- 设置合理的 maxmemory,可以根据实际情况设置 Redis 的 maxmemory,避免 Redis 在运行过程中出现内存不足的情况(大白话就是加钱加内存);
- 开启 Redis 的持久化功能,以将 Redis 中的数据持久化到磁盘中,避免数据丢失,并且在 Redis 重启后可以快速地恢复加载数据;
- 使用 Redis 的分区功能,将 Redis 中的数据分散到多个 Redis 实例中,以减轻单个 Redis 实例内存淘汰的负载压力;
- 与删除过期 key 一样,针对淘汰 key 也可以开启layz-free,把淘汰 key 释放内存的操作放到后台线程中执行。
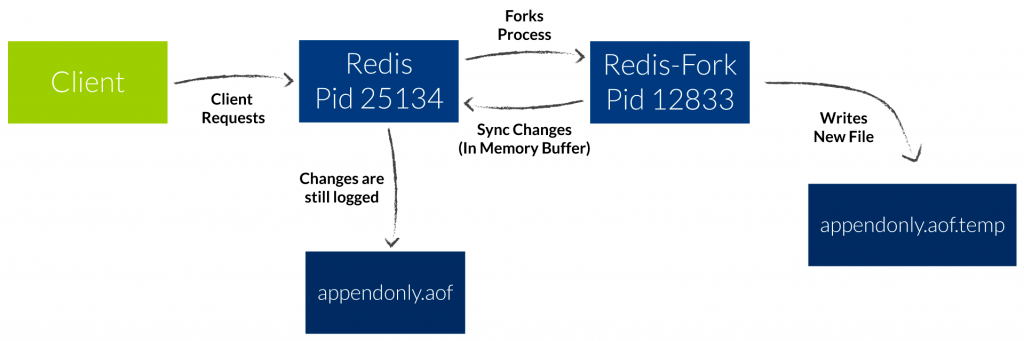
为了保证 Redis 数据的安全性,我们可能会开启后台定时 RDB 和 AOF rewrite 功能:
而为了在后台生成RDB文件,或者在启用 AOF持久化的情况下追加写只读 AOF文件,Redis 都需要 fork一个子进程, fork操作(在主线程中运行)本身可能会导致延迟。
下图分别是AOF持久化和 RDB持久化的流程图:
在大多数类 Unix 系统上,fork的成本都很高,因为它涉及复制与进程相关联的许多对象,尤其是与虚拟内存机制相关联的 页表。
例如,在linux/AMD64系统上,内存被划分为 4kB的页(如不开启内存大页);而为了将虚拟地址转换为物理地址,每个进程存储了一个页表,该页表包含该进程的地址空间每一页的至少一个指针;一个大小为 24 GB的 Redis 实例就会需要一个 24 GB / 4 kB * 8 = 48 MB的页表。
在执行后台持久化时,就需要fork此实例,也就需要为页表分配和复制 48MB的内存;这无疑会耗费大量 CPU 时间,特别是在部分虚拟机上,分配和初始化大内存块本身成本就更高。
可以看到在Xen上运行的某些 VM的 fork耗时比在物理机上要高一个数量级到两个数量级。
如何查看 fork 耗时:
我们可以在 redis-cli上执行 INFO 命令,查看 latest_fork_usec项:
INFO latest_fork_usec# 上一次 fork 耗时,单位为微秒latest_fork_usec:59477
这个时间就是主进程在 fork子进程期间,整个实例阻塞无法处理客户端请求的时间;这个时间对于大多数业务来说无疑是不能过高的(如达到秒级)。
除了定时的数据持久化会生成 RDB之外,当主从节点第一次建立数据同步时,主节点也会创建子进程生成 RDB,然后发给从节点进行一次全量同步,所以,这个过程也会对 Redis 产生性能影响。
解决方案:
- 更改持久化模式 如果 Redis 的持久化模式为RDB,我们可以尝试使用 AOF模式来减少持久化的耗时的突增(AOF rewrite 可以是多次的追加写)。
- 优化写入磁盘的速度 如果 Redis 所在的磁盘写入速度较慢,我们可以尝试将 Redis 迁移到写入速度更快的磁盘上。
- 控制 Redis 实例的内存 用作缓存的 Redis 实例尽量在 10G 以下,执行 fork 的耗时与实例大小有关,实例越大,耗时越久。
- 避免虚拟化部署 Redis 实例不要部署在虚拟机上,fork 的耗时也与系统也有关,虚拟机比物理机耗时更久。
- 合理配置数据持久化策略 于低峰期在 slave 节点执行 RDB 备份;而对于丢失数据不敏感的业务(例如把 Redis 当做纯缓存使用),可以关闭 AOF 和 AOF rewrite。
- 降低主从库全量同步的概率 适当调大 repl-backlog-size参数,避免主从全量同步。
在上面提到的定时 RDB 和 AOF rewrite 持久化功能中,除了fork本身带来的页表复制的耗时外,还会有 内存大页带来的延迟。
内存页是用户应用程序向操作系统申请内存的单位,常规的内存页大小是 4KB,而 Linux 内核从 2.6.38 开始,支持了 内存大页机制,该机制允许应用程序以 2MB大小为单位,向操作系统申请内存。
在开启内存大页的机器上调用bgsave或者 bgrewriteaoffork 出子进程后,此时 主进程依旧是可以接收写请求的,而此时处理写请求,会采用 Copy On Write(写时复制)的方式操作内存数据(两个进程共享内存大页,仅需复制一份 页表)。
在写负载较高的 Redis 实例中,不断处理写命令将导致命令针对几千个内存大页(哪怕只涉及一个内存大页上的一小部分数据更改),导致几乎整个进程内存的COW,这将造成这些写命令巨大的延迟,以及巨大的额外峰值内存。
同样的,如果这个写请求操作的是一个 bigkey,那主进程在拷贝这个 bigkey 内存块时,涉及到的内存大页会更多,时间也会更久,十恶不赦的 bigkey在这里又一次影响到了性能。
无疑在开启AOF / RDB时,我们需要关闭内存大页。我们可以使用以下命令查看是否开启了内存大页:
$ cat /sys/kernel/mm/transparent_hugepage/enabled[always] madvise never
如果该文件的输出为 [always]或 [madvise],则透明大页是启用的;如果输出为 [never],则透明大页是禁用的
在 Linux 系统中,可以使用以下命令来关闭透明大页:
typeCopy codeecho never > /sys/kernel/mm/transparent_hugepage/enabledecho never > /sys/kernel/mm/transparent_hugepage/defrag
第一行命令将透明大页的使用模式设置为 never,第二行命令将透明大页的碎片整理模式设置为 never;这样就可以关闭透明大页了。
AOF 和磁盘 I/O 造成的延迟
针对AOF(Append Only File)持久化策略来说,除了前面提到的 fork子进程追加写文件会带来性能损耗造成延迟。
首先我们来详细看一下AOF的实现原理,AOF 基本上依赖两个 系统调用来完成其工作;一个是 WRITE(2),用于将数据写入 Append Only文件,另一个是 fDataync(2),用于刷新磁盘上的 内核文件缓冲区,以确保用户指定的持久性级别,而 WRITE(2)和 fDatync(2)调用都可能是延迟的来源。
对 WRITE(2)来说,当系统范围的磁盘缓冲区同步正在进行时,或者当输出缓冲区已满并且内核需要刷新磁盘以接受新的写入时, WRITE(2)都会因此阻塞。
对fDataync(2)来说情况更糟,因为使用了许多内核和文件系统的组合,我们可能需要几毫秒到几秒的时间才能完成 fDataync(2),特别是在某些其它进程正在执行 I/O 的情况下;因此, Redis 2.4之后版本会尽可能在另一个线程执行 fDataync(2)调用。
解决方案:
最直接的解决方案当然是从 redis 配置出发,那么有哪些配置会影响到这两个系统调用的执行策略呢。我们可以使用appendfsync配置,该配置项提供了三种磁盘缓冲区刷新策略
- no当appendfsync被设置为 no时,redis 不会再执行 fsync,在这种情况下唯一的延迟来源就只有 WRITE(2)了,但这种情况很少见,除非磁盘无法处理 Redis 接收数据的速度(不太可能),或是磁盘被其他 I/O 密集型进程严重减慢。 这种方案对 Redis 影响最小,但当 Redis 所在的服务器宕机时,会丢失一部分数据,为了数据的安全性,一般我们也不采取这种配置。
- everysec当appendfsync被设置为 everysec时,redis 每秒执行一次 fsync,这项工作在非主线程中完成⚠️ 需要注意的是:对于用于追加写入 AOF文件的 WRITE(2)系统调用,如果执行时 fsync仍在进行中,Redis 将使用一个缓冲区将 WRITE(2)调用延迟两秒(因为在 Linux上,如果正在对同一文件进行 fsync, WRITE就会阻塞);但如果 fsync花费的时间太长,即使 fsync仍在进行中,Redis 最终也会执行 WRITE(2)调用,造成延迟。针对这种情况,Redis 提供了一个配置项,当子进程在追加写入 AOF文件期间,可以让后台子线程不执行刷盘(不触发 fsync 系统调用)操作,也就是相当于在追加写 AOF期间,临时把 appendfsync设置为了 no,配置如下: # AOF rewrite 期间,AOF 后台子线程不进行刷盘操作
# 相当于在这期间,临时把 appendfsync 设置为了 none
no-appendfsync-on-rewrite yes
当然,开启这个配置项,在追加写 AOF期间,如果实例发生宕机,就会丢失更多的数据。
- always当appendfsync被设置为 always时,每次写入操作时都执行 fsync,完成后才会发送 response回客户端(实际上,Redis 会尝试将同时执行的多个命令聚集到单个 fsync 中)。在这种模式下,性能通常非常差,如果一定要达到这个持久化的要求并使用这个模式,就需要使用能够在短时间内执行 fsync的 高速磁盘以及 文件系统实现。
大多数 Redis 用户使用no或 everysec
并且为了最小化AOF带来的延迟,最好也要 避免其他进程在同一系统中执行 I/O;当然,使用 SSD磁盘也会有所帮助(加 ),但通常情况下,即使是非 SSD 磁盘,如果磁盘没有被其它进程占用,Redis 也能在写入 Append Only File时保持良好的性能,因为 Redis 在写入 Append Only File时不需要任何 seek操作。
我们可以使用strace命令查看 AOF带来的延迟:
sudo strace -p $(pidof redis-server) -T -e trace=fdatasync
上面的命令将展示 Redis 在主线程中执行的所有fdatync(2)系统调用,但当 appendfsync配置选项设置为 everysec时,我们监控不到 后台线程执行的 fdatync(2);为此我们需将 -f option加到上述命令中,这样就可以看到子线程执行的 fdatync(2)了。
如果需要的话,我们还可以将write添加到 trace项中以监控 WRITE(2)系统调用:
sudo strace -p $(pidof redis-server) -T -e trace=fdatasync,write
但是,由于WRITE(2)也用于将数据写入客户端 socket以回复客户端请求,该命令也会显示许多与磁盘 I/O 无关的内容;为了解决这个问题我们可以使用以下命令:
sudo strace -f -p $(pidof redis-server) -T -e trace=fdatasync,write 2>&1 | grep -v '0.0' | grep -v unfinished SWAP 导致的延迟
Linux(以及许多其它现代操作系统)能够将内存页面从内存重新定位到磁盘,反之亦然,以便有效地使用系统内存。
如果内核将 Redis 内存页从内存移动到SWAP 分区,则当存储在该内存页中的数据被 Redis 使用时(例如,访问存储在该内存页中的 key),内核将停止 Redis 进程,以便将该内存页移回内存;这是一个涉及 随机I/O的缓慢磁盘操作(与访问已在内存中的内存页相比慢一到两个数量级),并将导致 Redis 客户端的异常延迟。
Linux 内核执行 SWAP主要有以下三个原因:
- 系统已使用内存达到内存上限,有可能是 Redis 使用的内存超过了系统可用内存,也可能是其它进程导致的;
- Redis 实例的数据集或数据集的一部分几乎是完全空闲的(客户端从未访问过),因此内核可以交换内存中的空闲内存页到磁盘;这种问题非常少见,因为即使是中等速度的实例也会经常接触所有内存页,迫使内核将所有内存页保留在内存中;
- 一些进程在系统上产生大量读写 I/O。因为文件通常是缓存的,所以它往往会给内核带来增加文件系统缓存的压力,从而产生SWAP;当然,这里说的进程也包括可能产生大文件的 Redis RDB和 AOF后台线程。
我们可以通过以下命令查看 Redis 的SWAP情况:
首先我们获取到 redis-server的 pid:
$ redis-cli info | grep process_idprocess_id:9
接下来查看Redis Swap的使用情况:
# $pid改为刚刚获取到的redis-server的pidcat /proc/$pid/smaps | egrep '^(Swap|Size)'
产生类似下面的输出:
Size: 316 kBSwap: 0 kBSize: 4 kBSwap: 0 kBSize: 8 kBSwap: 0 kBSize: 40 kBSwap: 0 kBSize: 132 kBSwap: 0 kBSize: 720896 kBSwap: 12 kBSize: 4096 kBSwap: 156 kBSize: 4096 kBSwap: 8 kBSize: 4096 kBSwap: 0 kBSize: 4 kBSwap: 0 kBSize: 1272 kBSwap: 0 kBSize: 8 kBSwap: 0 kBSize: 4 kBSwap: 0 kBSize: 16 kBSwap: 0 kBSize: 84 kBSwap: 0 kBSize: 4 kBSwap: 0 kBSize: 4 kBSwap: 0 kBSize: 8 kBSwap: 4 kBSize: 8 kBSwap: 0 kBSize: 4 kBSwap: 0 kBSize: 4 kBSwap: 4 kBSize: 144 kBSwap: 0 kBSize: 4 kBSwap: 0 kBSize: 4 kBSwap: 4 kBSize: 12 kBSwap: 4 kBSize: 108 kBSwap: 0 kBSize: 4 kBSwap: 0 kBSize: 4 kBSwap: 0 kBSize: 272 kBSwap: 0 kBSize: 4 kBSwap: 0 kB
每一行 Size 表示 Redis 所用的一块内存大小,Size 下面的 Swap 就表示这块 Size 大小的内存有多少数据已经被换到磁盘上了。
但如果存在SWAP比例较大的输出,那么 Redis 的延迟很大可能就是 SWAP导致的。我们可以使用 vmstat命令进一步验证:
$ vmstat 1procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 0 0 3980 697932 147180 1406456 0 0 2 2 2 0 4 4 91 0 0 0 3980 697428 147180 1406580 0 0 0 0 19088 16104 9 6 84 0 0 0 3980 697296 147180 1406616 0 0 0 28 18936 16193 7 6 87 0 0 0 3980 697048 147180 1406640 0 0 0 0 18613 15987 6 6 88 0 2 0 3980 696924 147180 1406656 0 0 0 0 18744 16299 6 5 88 0 0 0 3980 697048 147180 1406688 0 0 0 4 18520 15974 6 6 88 0
我们看到si和 so这两列,它们分别是内存中 SWAP到文件的 Size 以及从文件中 SWAP到内存的 Size;如果这两列中存在非零值,则表示系统中存在 SWAP活动。
最后我们还可以使用IOStat命令查看系统的全局 I/O活动:
$ iostat -xk 1avg-cpu: %user %nice %system %iowait %steal %idle 13.55 0.04 2.92 0.53 0.00 82.95Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %utilsda 0.77 0.00 0.01 0.00 0.40 0.00 73.65 0.00 3.62 2.58 0.00sdb 1.27 4.75 0.82 3.54 38.00 32.32 32.19 0.11 24.80 4.24 1.85
解决方案:
这种情况下基本没有什么可以多说的解决方案,无非就两方面:
- 加内存(加 ),没有什么是怼资源无法解决的;
- 减少业务侧对 Redis 的使用量,包括调整过期时间、优化数据结构、调整缓存策略等等;
另一方面自然是做好 Redis 机器的内存监控以及SWAP事件监控,在内存不足及 SWAP事件激增时及时告警。
内存碎片
Redis 内存碎片率(used_memory_rss / used_memory)大于 1表示正在发生碎片,内存碎片率超过 1.5 表示碎片过多,Redis 实例消耗了其实际申请的物理内存的 150%的内存;另一方面,如果 内存碎片率低于 1,则表示 Redis 需要的内存多于系统上的可用内存,这会导致 SWAP 操作,其中内存交换到磁盘的 CPU 时间成本将导致 Redis 延迟显著增加。
为什么会产生内存碎片:
主要有两大原因:
- redis自己实现的内存分配器:在 redis中新建 key-value值时, redis需要向操作系统申请内存,一般的进程在不需要使用申请的内存后,会直接释放掉、归还内存;但 redis不一样, redis在使用完内存后并不会直接归还内存,而是放在 redis自己实现的内存分配器中管理,这样就不需要每次都向操作系统申请内存了,实现了高性能;但另一方面,未归还的内存自然也就造成了 内存碎片。
- value的更新: redis的每个 key-value对初始化的内存大小是最适合的,当这个 value改变的并且原来内存块不适用的时候,就需要重新分配内存了;而重新分配之后,就会有一部分内存 redis无法正常回收,造成了 内存碎片。
我们可以通过执行 INFO 命令快速查询到一个 Redis 实例的内存碎片率(mem_fragmentation_ratio):
[db0] > INFO memory# Memoryused_memory:215489640used_memory_human:205.51M...mem_fragmentation_ratio:1.13mem_fragmentation_bytes:27071448...
理想情况下,操作系统将在物理内存中分配一个连续的段,Redis 的内存碎片率等于 1 或略大于 1;碎片率过大会导致内存无法有效利用,进而导致 redis 频繁进行内存分配和回收,从而导致用户请求延迟,并且这个延迟是不会计入slowlog的。
如何清理内存碎片:
若在Redis < 4.0的版本,如果内存碎片率高于 1.5,直接重启 Redis 实例就可以让操作系统恢复之前因碎片而无法使用的内存;但在这种情况下,也许监控并发出告警就足够了,直接重启在大多数场景下并不适用;但当内存碎片率低于 1 时,我们就需要一个高级别的告警,以快速增加可用内存或减少内存使用量。
Redis ≥ 4.0开始,当 Redis 配置为使用包含的 jemalloc副本时,可以使用主动碎片整理功能;它可以配置为在碎片达到一定百分比时启动,将数据复制到 连续的内存区域并释放旧数据,从而减少内存碎片。
redis-cli开启自动内存碎片清理:
127.0.0.1:6379[6]> config set activedefrag yesOK
redis.conf中相关的配置项:
# Enabled active defragmentation# 碎片整理总开关# activedefrag yes# Minimum amount of fragmentation waste to start active defrag# 内存碎片达到多少的时候开启整理active-defrag-ignore-bytes 100mb# Minimum percentage of fragmentation to start active defrag# 碎片率达到百分之多少开启整理active-defrag-threshold-lower 10# Maximum percentage of fragmentation at which we use maximum effort# 碎片率小余多少百分比开启整理active-defrag-threshold-upper 100
当然,在面对一些复杂的场景时我们希望能根据自己设计的策略来进行内存碎片清理,redis也提供了手动内存碎片清理的命令:
127.0.0.1:6379> memory purgeOK 绑定 CPU 单核
很多时候,我们在部署服务时,为了提高服务性能,降低应用程序在多个 CPU 核心之间的上下文切换带来的性能损耗,通常采用的方案是进程绑定 CPU 的方式提高性能。
但 Vanilla Redis并不适合绑定到单个 CPU 核心上。一般现代的服务器会有多个 CPU,而每个 CPU 又包含多个 物理核心,每个 物理核心又分为多个 逻辑核心,每个物理核下的逻辑核共用 L1/L2 Cache。而 Redis 会 fork出非常消耗 CPU 的后台任务,如 BGSAVE或 BGREWRITEAOF、异步释放 fd、异步 AOF 刷盘、异步 lazy-free 等等。如果把 Redis 进程只绑定了一个 CPU 逻辑核心上,那么当 Redis 在进行数据持久化时,fork 出的子进程会 继承父进程的 CPU 使用偏好
此时子进程就要占用大量的 CPU 时间,与主进程发生 CPU 争抢,进而影响到主进程服务客户端请求,访问延迟变大。
解决方案:
- 绑定多个逻辑核心如果你确实想要绑定 CPU,可以优化的方案是,不要让 Redis 进程只绑定在一个 CPU 逻辑核上,而是绑定在多个逻辑核心上,而且,绑定的多个逻辑核心最好是同一个物理核心,这样它们还可以共用 L1/L2 Cache。当然,即便我们把 Redis 绑定在多个逻辑核心上,也只能在一定程度上缓解主线程、子进程、后台线程在 CPU 资源上的竞争,因为这些子进程、子线程还是会在这多个逻辑核心上进行切换,依旧存在性能损耗。
- 针对各个场景绑定固定的 CPU 逻辑核心Redis 6.0 以上的版本中,我们可以通过以下配置,对主线程、后台线程、后台 RDB 进程、AOF rewrite 进程,绑定固定的 CPU 逻辑核心:# Redis Server 和 IO 线程绑定到 CPU核心 0,2,4,6
server_cpulist 0-7:2
# 后台子线程绑定到 CPU核心 1,3
bio_cpulist 1,3
# 后台 AOF rewrite 进程绑定到 CPU 核心 8,9,10,11
aof_rewrite_cpulist 8-11
# 后台 RDB 进程绑定到 CPU 核心 1,10,11
# bgsave_cpulist 1,10-1
如果使用的正好是 Redis 6.0 以上的版本,就可以通过以上配置,来进一步提高 Redis 性能;但一般来说,Redis 的性能已经足够优秀,除非对 Redis 的性能有更加严苛的要求,否则不建议绑定 CPU。
Redis 排障是一个循序渐进的复杂流程,涉及到 Redis 运行原理,设计架构以及操作系统,网络等等。
作为业务方的 Redis 使用者,我们需要了解 Redis 的基本原理,如各个命令的时间复杂度、数据过期策略、数据淘汰策略以及读写分离架构等,从而更合理地使用 Redis 命令,并结合业务场景进行相关的性能优化。
Redis 在性能优秀的同时,又是脆弱的;作为 Redis 的运维者,我们需要在部署 Redis 时,需要结合实际业务进行容量规划,预留足够的机器资源,配置良好的网络支持,还要对 Redis 机器和实例做好完善的监控,以保障 Redis 实例的稳定运行。