java数据结构及算法总结
数组:
数组是一种连续存储线性结构,元素类型相同,大小相等,数组是多维的,通过使用整型索引值来访问他们的元素,数组尺寸不能改变。
- 数组的优点:
- 存取速度快
- 数组的缺点:
- 事先必须知道数组的长度
- 插入删除元素很慢
- 空间通常是有限制的
- 需要大块连续的内存块
- 插入删除元素的效率很低
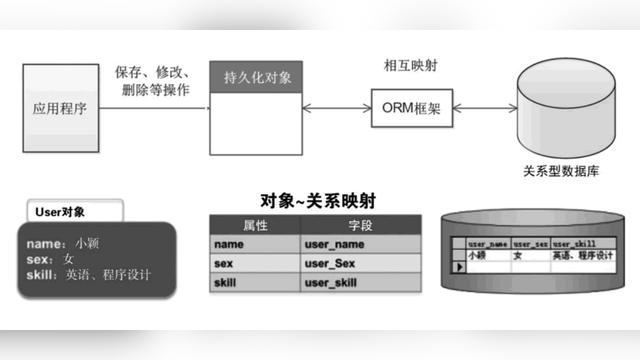
1.collection 和 collections
collection :集合类的上层接口,子接口主要有list ,set,queue等
collections:提供对集合进行搜索,排序,替换和线程安全化等操作的工具类。
arrayList,LinkedList,Vector
arraylist:动态数组;基于数组实现;
linkedList:有序数组;基于双向链表实现;
vector:对象容器,可放入不同类的对象(基于数组实现);
linkedHashMap ,TreeMap ,TreeSet
linkedHashMap:顺序存取hashMap(基于数组和双向链表实现);
TreeMap:内部排序(基于黑色树实现);
TreeSet:有序的set集合(基于二叉树);
链表:
n个节点离散分配,彼此通过指针相连,每个节点只有一个前驱节点,每个节点只有一个后续节点,首节点没有前驱节点,尾节点没有后续节点。
确定一个链表我们只需要头指针,通过头指针就可以把整个链表都能推出来。

- 链表优点
- 空间没有限制
- 插入删除元素很快
- 链表缺点
- 存取速度很慢
链表又细分了3类:
- 单向链表
- 一个节点指向下一个节点。
- 双向链表
- 一个节点有两个指针域。
- 循环链表
- 能通过任何一个节点找到其他所有的节点,将两种(双向/单向)链表的最后一个结点指向第一个结点从而实现循环。
操作链表要时刻记住的是:节点中指针域指向的就是另一个节点!
栈和队列
数组和链表都是线性存储结构的基础,栈和队列都是线性存储结构的应用。
我们将栈可以看成一个放光盘的箱子,箱口与略大与光盘。然后
- 往箱子里面放东西叫做入栈
- 往箱子里面取东西叫做出栈
- 箱子的底部叫做栈底
- 箱子的顶部叫做栈顶

说到栈的特性,有一句经典的言语来概括:先进后出,后进先出。
JAVA实现栈
- 使用数组实现的叫静态栈
- 使用链表实现的叫动态栈
队列
队列非常好理解,我们将队列可以看成我们平时排队打饭。
- 有新的人加入了 -> 入队
- 队头的人打饭了 -> 出队
相对于栈而言,队列的特性是:先进先出,后进后出

队列
- 使用数组实现的叫静态队列
- 使用链表实现的叫动态队列
二叉树
树是一种非线性的数据结构,相对于线性的数据结构(链表、数组)而言,树的平均运行时间更短(往往与树相关的排序时间复杂度都不会高),
和现实中的树相比,编程的世界中的树一般是“倒”过来看,这样容易我们分析。

现实中的树是有很多很多个分支的,分支下又有很多很多个分支,如果在程序中实现这个会非常麻烦。因为本来树就是非线性的,而我们计算机的内存是线性存储的,太过复杂的话无法设计出来。
因此,就有了简单又经常用的 -> 二叉树,顾名思义,就是每个分支最多只有两个的树,上图就是二叉树。
- 一棵树至少会有一个节点(根节点)
- 树由节点组成,每个节点的数据结构包括一个数据和两个分叉
堆和堆栈
堆内存用来存放由new创建的对象和数组。
在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
'堆栈' 就是 '栈',称呼不同而已。
栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享。
堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
散列表
无论是Set还是Map,我们会发现都会有对应的-->HashSet,HashMap
首先我们也先得回顾一下数据和链表:
- 链表和数组都可以按照人们的意愿来排列元素的次序,他们可以说是有序的(存储的顺序和取出的顺序是一致的)
- 这会带来缺点:想要获取某个元素,就要访问所有的元素,直到找到为止,会消耗很多时间。
所以我们需要另外的存储结构:不在意元素顺序,能快速查找元素。其中就有一种常见方式:散列表。
散列表工作原理
散列表为每个对象计算出一个整数,称为散列码。根据这些计算出来的整数(散列码)保存在对应的位置上!即,散列码就是索引。
在Java中,散列表用的是链表数组实现的,每个列表称之为桶。
红黑树
是一种平衡二叉树,TreeSet、TreeMap底层都是红黑树来实现的。
二叉查找树也有个例(最坏)的情况(线性):

上面符合二叉树的特性,但是它是线性的,完全没树的用处,树是要“均衡”才能将它的优点展示出来,比如下面这种:

因此,就有了平衡树这么一个概念~红黑树就是一种平衡树,它可以保证二叉树基本符合均衡的金字塔结构。都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。
它的统计性能要好于平衡二叉树
上图就是一个红黑树,红黑树就字面上的意思,有红色的节点,有黑色的节点。
- 性质1. 节点是红色或黑色。
- 性质2. 根节点是黑色。
- 性质3. 每个叶节点(NIL节点,空节点)是黑色的。
- 性质4. 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 性质5. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
b树:
平衡二叉树的查找效率为O(log2N)与树的深度相关,通过降低树的深度,可以提高查找效率,但是还有一个瓶颈就是,每次查找一次就只能得到一个节点元素,如果查找一次能得到多个节点元素,那么在同样的高度就能够查找更多的元素,从而提高查找效率,因此提出多路查找树。
多路查找树(muitl-way search tree),其每一个结点的孩子数可以多于两个,且每个结点出可以存储多个元素。由于它是查找树,所有元素之间存在某种特定的排序关系。
B树就是一种平衡的多路查找树。
B-树
中所有结点中孩子结点个数的最大值成为B-树的阶,通常用m表示,从查找效率考虑,一般要求m>=3。一棵m阶B-树或者是一棵空树,或者是满足以下条件的m叉树。
1)每个结点最多有m个分支(子树);而最少分支数要看是否为根结点,如果是根结点且不是叶子结点,则至少要有两个分支,非根非叶结点至少有ceil(m/2)个分支,这里ceil代表向上取整。
2)如果一个结点有n-1个关键字,那么该结点有n个分支。这n-1个关键字按照递增顺序排列。
3)每个节点的结构为
节点个数:n;
关键字数组: k[n],这n个关键字按照递增顺序排列
孩子指针数组:p[n + 1], p0<=k1, 之后所有 ki < pi <= ki+1;
B+树
1)在B+树中,具有n个关键字的结点有n个分支,而在B-树中,具有n个关键字的结点含有n+1个关键字。
2)在B+树中,每个结点(除根结点外)中的关键字个数n的取值为ceil(m/2) <= n <=m,根结点的取值范围为1<=n<=m,b树他们的取值范围分别是ceil(m/2) -1<= n <=m-1和1<=n<=m-1。
3)在B+树中叶子结点包含信息,并且包含了全部关键字,叶子结点引出的指针指向记录。
4)在B+树中的所有非叶子结点仅起到一个索引的作用,即结点中的每个索引项只含有对应子树的最大关键字和指向该子树的指针。
算法:
1.二分查找:又称折半查找;优点是比较次数少,查询速度快,平均性能好,占用系统内存较少,其缺点是:要求待查表为有序表,且插入删除困难。
2.递归算法
递归简单理解就是方法自身调用自身。
排序算法:1.直接插入排序;2.希尔排序,3,选择排序,4.堆排序;5,冒泡排序6,快速排序,7,归并排序,8.基数排序
1.冒泡排序:他重复地走访要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来,走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成、整个算法的名字由来是因为越小的元素会经由交换慢慢‘浮’到数列的顶端。