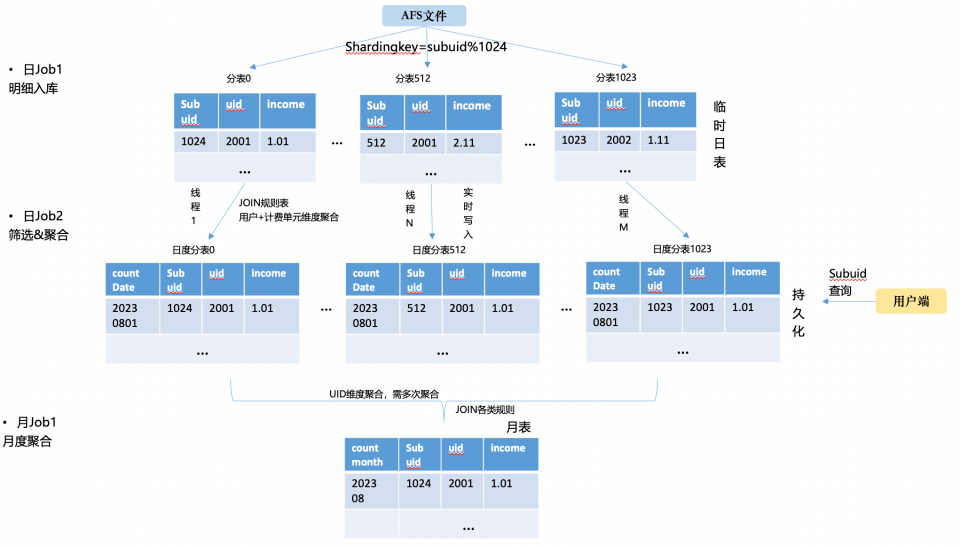
大型网站架构演进
不同企业,不同用户量的系统在不同发展阶段面临着不同的痛点。一个系统从小往上成长的过程,也就是大型网站架构演进的过程。
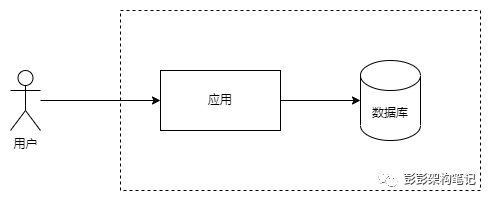
如上图。单主机阶段,这个阶段应用和数据库部署在同一个主机里。此时的用户量非常少,通常在1万以内。这个阶段的系统大多处于验证阶段,对高可用需求也是可有可无,对成本控制倒是非常敏感。
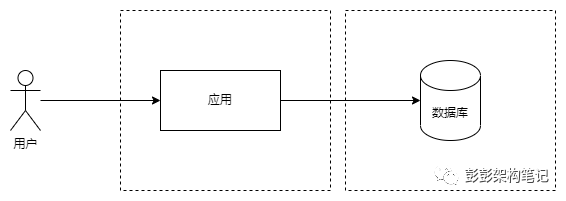
如上图。数据库分离单独部署阶段,这个阶段将数据库从原来的共用的那台主机里分离出来部署到数据库专用的主机上。随着用户规模的逐渐发展,单台主机已经逐渐支撑不住并发流量了,而且随着市场验证,数据的价值开始凸显,也有了对数据做备份的需求。于是数据库被单独分离出来部署到性能更好的主机上并做了初步的数据备份。

如上图。负载均衡阶段,这个阶段应用使用集群部署并使用负载均衡转发请求以分散单个主机节点压力。用户规模的持续增加让单个业务系统节点无法支撑高峰期所有的并发流量,于是应用被改造成无状态服务,而且在应用的前面使用了负载均衡器,由负载均衡器转发流量给应用。这个阶段虽偶尔有慢SQL产生,但一般能通过建索引等措施快速解决问题。

如上图。分布式缓存阶段,这个阶段增加了分布式缓存或多级缓存来减轻系统流量对数据库的读压力。在上一阶段由于应用无状态化改造后,应用的伸缩变得更容易了,随着应用节点的增多和用户流量的增加,系统的压力明显转向数据库了。此时的表现通常是慢SQL增多,或者虽然单个SQL查询走了索引执行计划也最佳,但架不住请求量太多。于时开始有了分布式缓存服务,将热点数据缓存起来并设置一定的过期策略,这样大量的读请求先到缓存查询没有结果再查数据库,大大减轻了对数据库的读压力。这个阶段大概能支持百万级注册用户了,多数的中小规模系统穷极一生大致也就处于这一阶段。

如上图。分布式文件系统阶段,这个阶段将系统中的图片和其它非结构化的文件单独使用分布式文件系统存取。在前面服务无状态改造时,对于此类附件类的文件一般会有各种共享存储或集中存储的方案,如使用FTP或者NAS共享存储的,但随着业务发展,这部分业务的IO性能和容量瓶颈已经到来,也就产生了将这部分业务剥离出来单独使用分布式文件系统来存取和管理的需求。
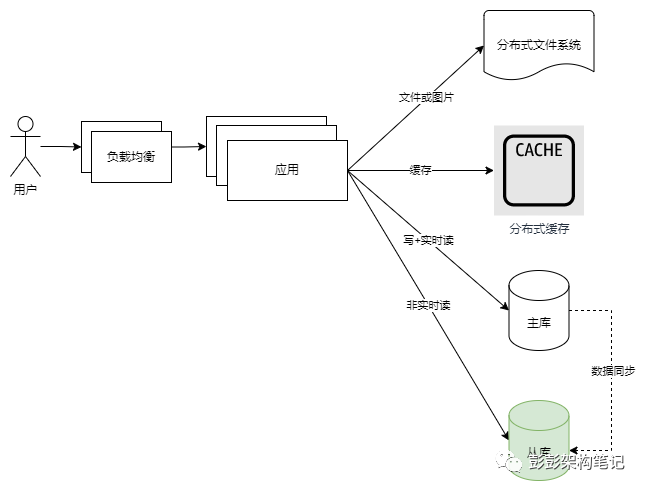
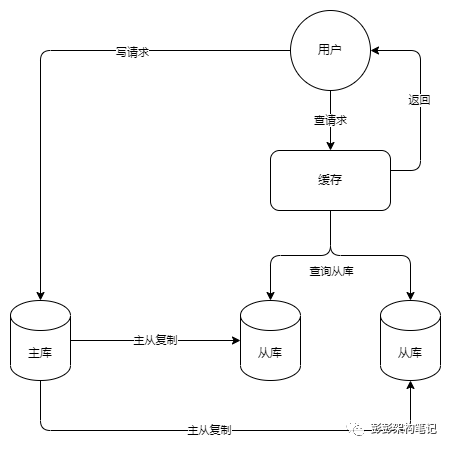
如上图。读写分离阶段,这个阶段将数据库分为主库和从库,新增的从库承担非实时读的职能。虽然前面增加了分布式缓存后,对数据库的热点读压力已经大幅度减少,但始终单个数据库的读能力仍然有上限。而且还有管理后台和报表这些非核心服务查询主库也造成了不小的压力,这类报表通常SQL复杂多变又难于添加缓存,对于此类非实时查询的业务,可以通过读写分离再次减轻主库的读压力。如果单个从库遇到读瓶颈了,还可以配置一主多从,提供更多的从库一起来承担非实时读压力。读写分离的架构图如下:

如上图。搜索分离阶段,这个阶段将搜索从数据库和系统中剥离出来使用专业的分布式搜索引擎实现。对于提供了C端搜索功能的业务系统,早期使用数据库实现的搜索效率非常低,在用户并发请求量大时会大幅拖累数据库。数据库对全文索引和地理位置的支持非常有限,所以使用分布式搜索引擎将这部分剥离出去独立实现。搜索分离其实本质是读写分离的一种特殊形式,读写分离是使用从库承担非实时读压力,而搜索分离是使用搜索引擎承担搜索业务读请求压力。

如上图。垂直分库阶段,这个阶段通常会配合子系统或微服务的建设将不同的业务领域的主库分离,形成每个业务领域一个主库多个从库的架构。截止到前面,我们扩展的都是系统的读能力,虽然多数业务是读多写少,但随着海量并发请求的到来,最终的瓶颈始终会出现在主库的写能力上,是时候考虑扩展写能力了。
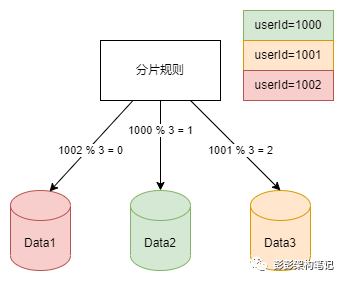
分表阶段,这个阶段通常是单表的容量或并发服务能力已经遇到了瓶颈,分为垂直分表和水平分表。垂直分表与垂直分库类似,垂直分库是按业务将一个大库垂直分多个小库,而垂直分表就是将一个大表按字段拆成多个字段较少的小表的过程。水平分表则是将一个表的记录按数据范围写到同一个库或者其他库中结构相同的表里,最常见的范围分表和哈希分表,如下图:
随着分布式数据库的发展,多数的分布式数据库原生就提供了数据分片和强大的伸缩能力。通过这些能力无需应用层的介入就能实现以前需要通过分库分表和读写分离才能达到的效果。虽然目前分布式数据库的技术仍然在发展和完善中,但趋势已经非常明显,技术的发展已经大幅度降低开发人员应对海量并发请求的技术门槛。
声明:本站部分内容来自互联网,如有版权侵犯或其他问题请与我们联系,我们将立即删除或处理。
▍相关推荐
更多网站架构相关>>>