推荐系统概述和主流模型介绍
Hello,大家好,欢迎来到“自由技艺”的知识小馆,今天我们来聊一聊推荐算法。
在广告、电商、信息流分发等业务场景中,推荐算法发挥着至关重要的作用,好的推荐算法能够把用户牢牢抓住,让用户的时间消耗在你推荐的内容上。当然,所推荐的内容有多少价值一般不是App所关注的,APP推荐的目的仅仅是留住用户。腾讯副总裁孙忠怀曾在公开场合说过:“现在短视频平台的个性化分发实在是太强大了,你喜欢‘猪食’,你看到的就全是‘猪食’”。
经典的推荐算法主要指协同过滤(CF),在深度学习火起来之后,基于神经网络的推荐模型层出不穷,比如 google Play 的 Wide & Deep、Youtube 的超大规模分类模型等。本文首先简单介绍下一个完整的推荐系统组成及算法流程,接着重点介绍下主流推荐模型的一些实现细节。
0 如何搭建一个完整的推荐系统
(1)推荐系统组成
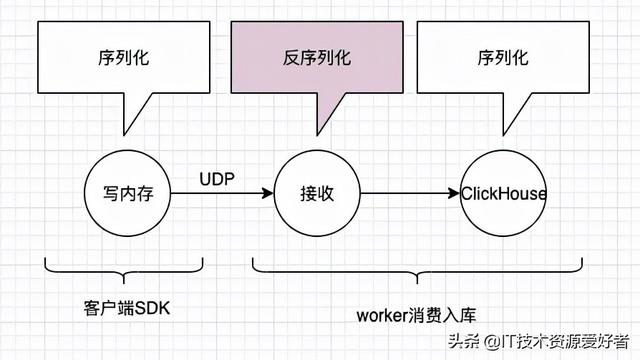
标签系统:为了实现内容的精准推荐,首先需要用户画像。所谓用户画像,就是给用户贴上各式各样的标签,比如年龄、性别、兴趣、浏览历史等等,这些标签可以分为事实标签、模型标签、预测标签等,另一方面,又可以按它表示的范围分为一级标签、二级标签、三级标签等。这些标签需要从原子数据集中提取,然后再量化。原子数据集又是什么?它指的是用户浏览 APP 的痕迹以及一些注册信息等,通过消息中间件、存储模块(比如 kafka、Hbase)收集、存储。

自动化标签系统
算法库:标签系统生成了多维度、较丰富、较全面的用户标签,也就是特征,这些特征就是各种推荐算法或模型的输入数据。
离线训练:有了输入数据和推荐模型还不够,只有通过训练,才能获得最优的模型参数。为什么不用在线训练呢?一是没必要,二是会造成很大的性能开销。
A/B 测试:推荐模型训练好了之后,怎么评估推荐效果呢?这就用到了 A/B 测试,A/B 测试是一种常用的在线评估算法效果的方法。简单来说,就是按一定的规则将用户随机分成几组,并对不同组的用户采用不同的算法,然后通过统计不同组用户的各种评测指标,比如点击率、浏览率、购买率等,从而比较不同算法的好坏。
实时推荐:一旦选中了最好的推荐算法,就可以部署到线上了。
冷启动:推荐系统总体上来说,还是一种有监督的学习方法。有监督学习必然需要样本和标签,而在产品上线初期,系统对用户了解很少,这时只能通过专家知识进行推荐。当系统积累了一定量的数据或者拿到用户足够多的反馈后,就可以训练机器学习模型了。
(2)推荐算法流程
推荐服务的流程主要有 3 步:获取用户特征 -> (召回) -> 调用推荐模型 -> (粗排、精排)。
在实际应用中,物品列表规模很大,如果对所有的物品都调用模型打分,在性能上是不可接受的,因为计算耗时过长从而影响用户体验。
所以,一种常见的做法是将推荐列表生成分为召回和排序两步。召回的作用是从大量的候选物品中(例如上百万)筛选出一批用户较可能喜欢的候选集 (一般是几百)。排序又分为粗排和精排,粗排就是选出打分最高的那一部分物品。更进一步,对粗排得到的物品列表,可能需要人工调整,这就是精排。
1 CF(Collaborative Filtering,协同过滤)
好了,到这里我们已经对推荐系统有了宏观上的了解了。接下来就来看看推荐算法是怎么筛选出用户感兴趣的物品的,最经典的就是协同过滤算法,分为 UserCF 和 ItemCF,简单理解就是一句话:人以类聚,物以群分。这方面的文章很多了,这里就不展开讲了,下图给出了 UserCF 和 ItemCF 的优劣势对比的结果。

UserCF 和 ItemCF 对比
2 MF(Matrix Factorization,矩阵分解)
现在来考虑一个给用户推荐电影的简单场景:假设有 m 个用户,总的电影种类为 n. 例如,用户 1 看过电影 1 和电影 n,并给出了评分 1.0 和 0.5,如果用户看完电影没给评分,也没关系,可以用一个默认值代替。用户 2 看过电影 2,并打出了 3.7 分。推荐的目的就是把这个 m * n 的矩阵中(用 S 表示)缺失的值给补全,具体流程如下:

CF 矩阵
首先,我们假设矩阵 S 可以分解为矩阵 P 和 Q 的乘积,

CF 矩阵分解
这样做的物理含义就是:每个用户或者每部电影都可以用一个长度为 k 的向量表示。
模型 一:NCF(Neural CF)

NCF 模型
上述模型中,输入层(Input Layer)需要对用户(User)和物品(Item)进行独热编码(one-hot),矩阵 P 和 矩阵 Q 是模型中的参数。输出层(Output Layer)是 softmax 层,神经元个数是 1. 当输出 y 为 1 时,表示用户 u 和 物品 i 是相关的,也就是说,物品 i 可以推荐给用户 u;当输出为 0 时,表示用户 u 和 物品 i 是无关的,也就是说,物品 i 不建议推荐给用户 u.
模型二:DCF(Deep CF)
下面要介绍的这个矩阵分解模型特别简单粗暴,把用户和物品的隐向量直接当作神经网络中的参数去求解,而输出层根据余弦相似度的结果去判断用户 i 和物品 j 的相似度。

DCF 模型
3 FM(Factorization machine,因子分解机)
上一章中的模型一和模型二是比较标准的 MF 模型,然而它有很多缺点:首先,每遇到一个新的业务,都需要重新搭建模型,如推导出新的参数学习算法,并在学习参数过程中调节各种参数,不能很好地复用。其次,MF 模型不能很好地利用特征工程法( feature engineering)来完成学习任务。
模型一:FM
一般来说做推荐 CTR(Click Through Rate)预估时最简单的思路就是将特征做线性组合(LR),传入 sigmoid 得到一个概率值,本质上这就是一个线性模型,因为 sigmoid 是单调增函数不会改变里面的线性模型的 CTR 预测顺序,因此 LR 模型效果会比较差。也就是 LR 的缺点:
- 是一个线性模型
- 每个特征对最终输出结果独立,需要手动特征交叉(xi*xj),比较麻烦

LR 目标函数

LR 目标函数改良版
上式是 LR 目标函数的一个简单改良版,但是还是存在问题:只有当 xi 与 xj 均不为 0 时,二阶交叉项才会生效,后面这个特征交叉项本质是和多项式核 SVM(Support Vector Machine,支持张量机)等价的。为了解决这个问题,FM 模型应运而生!

FM 目标函数
从公式来看,FM 模型就是 LR - 线性组合加上交叉项 - 特征组合。所以,从模型表达能力上来看,FM 肯定是要强于 LR 的,至少它不会比 LR 弱,当交叉项参数wij全为0的时候,整个模型就退化为普通的 LR 模型。对于有 n 个特征的模型,经过两两特征组合之后,维度自然而然就高了。
模型二:GBDT + FM
GBDT,全称 Gradient Boosting Decision Tree(梯度提升决策树),它是一个集成模型,使用多棵决策树,每棵树去拟合前一棵树的残差来得到很好的拟合效果。
由于 GBDT 是不支持高维稀疏的特征,所以设计了 GBDT + FM 的模型如图所示:

GBDT + FM 模型
4 Wide & Deep
谷歌在 2016年发表了一篇论文“Wide & Deep Learning for Recommender Systems”,业务场景是 Google Play 基于用户 query,推荐合适的 item,文章很短,只有 4 页,却产生了很大的影响。

Wide & Deep 模型
上图模型分为两部分:分别是左边的 Deep 和右边的 Wide。
模型的输入数据包含连续特征(连续值),如年龄、已安装的 APP 数量、已连接的会话数等和类别特征,如用户画像、设备类型、已安装的 APP 和用户可能感兴趣的 APP。
Wide 模型中,将用户已安装的 APP 和可能感兴趣的 APP 做叉积运算,然后连接到 softmax 层。
Deep 模型中,由于输入特征维度很大,先经过嵌入层(Embedding)降维处理,然后特征聚合,经过全联接层,最后一层也是 softmax 层。
Wide 是一个 LR(Logistic Regression)模型,它是一个线性模型,利用了交叉特征(AND),显然具备较强的记忆能力(memorization)。
而 Deep 是一个 DNN 模型,它可以通过针对稀疏特征学习的低维密集嵌入更好地推广到看不见的特征组合,因此几乎不需要人工特征工程,具备较强的泛化能力(generalization)。但是当交互信息较少时,它会过拟合(overfit),学习到一些本来不存在的关联。
5 超大规模分类问题
YouTube 在2016年发表的论文《Deep Neural Networks for YouTube Recommendations》中提出了基于深度学习的一个超大规模分类模型(Candidate Generation,类似 skip-gram,采用方法:hierarchical softmax 和 negative sample),它把召回阶段建模为一个分类模型,其目标是根据上下文 C,用户 U,从集合 V 中找到时刻 t 最可能被观看的视频 Wt

Youtube 超大规模多分类模型
u 代表用户和 context 的 embedding,v 代表 video 的 embedding。深度学习的任务是从用户观看的历史数据和当前上下文中学习用户的 embedding.
用户的观看历史是一个系数的、变长的视频id序列;
用户画像特征:如地理位置、设备、性别、年龄、登录状态等连续或离散特征都被归一化为[0,1],和 watch vector 以及 search vector 做拼接(concat);
example age:该特征表示视频被上传之后的时间;
目标函数是
watch_minutes_per_impression,而不是 ctr 的函数,主要避免 click-bait 问题
6 基于图的随机游走算法
二分图模型的代表是 Personal Rank 和 Page Rank 算法,其核心思想是:建立用户和物品之间的二分图,如果样本中某个用户关联了某个物品,那么该用户点和物品点之间建立一条边;对于图中的每个点,以一定的概率 a 停留在原地,以概率 1 - a 走向与它相邻的节点,这是一个马尔可夫过程,经过多轮迭代之后,最终每个点的到达概率都会收敛到某个值。

二分图模型
总结
回过头来重新审视下推荐系统,它通常可分为两部分:召回和排序。
协同过滤属于召回的算法,目的是得到一个比较小的推荐列表,代表算法就是 MF 和基于神经网络的超大规模分类模型。
而从小的推荐列表中筛选出最终的推荐列表,就需要排序。排序的前提是要给某种环境下的用户和物品之间的匹配度打分,通常是 0 到 1 之间的一个小数。然后再取排名靠前的物品作为最终要推荐的物品,这一过程又叫做 CTR 预估。常见的排序模型有 LR、GBDT、FM 等。
一个好的推荐系统中一般存在多个模型,而每个模型的最佳效果需要工程师在实践中摸索调试出来的,每个基础模型又有很多改良版本,针对不同的问题效果也可能不同。所以,后续文章中,我们将继续深入研究模型细节,并深入理解模型背后的设计思想,也欢迎读者关注我的头条号“自由技艺”。