通过API网关实现微服务管控-限流,熔断和降级

今天准备谈下基于API网关来实现微服务治理管控中的服务限流,熔断和降级方面的内容。在前面谈微服务架构的时候也谈到过类似通过Hystrix,Sentinel来是服务限流熔断。包括也不断地在谈去中心化架构和服务网格化。
但是通过API网关来实现微服务治理,短期仍然是一个必要选择。
其原因主要体现在以下几个方面:
其一是场景需求,即面对一个大集成项目,或多个开发商进行协同集成的场景,采用API网关是必须的。一个开发商内部可以去中心化,但是多个开发商间想要去中心化不容易。
其二是在微服务架构开发里面,单个微服务应该尽量简单,就是实现业务规则逻辑和暴露API接口服务能力。但是当前的微服务开发框架,在实现类似限流熔断等的时候,基本都需要对已经开发完成的微服务进行相关的配置修改或增加注解等。
其三对于ServiceMesh服务网格当前还没有大足够成熟和大面积应用的阶段,但是API网关本身已经足够成熟并得到大量项目实践验证。
基于API网关进行服务接入和管控

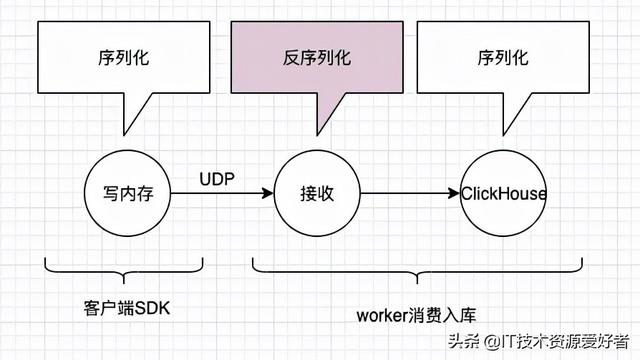
对于API网关我前面已经写过很多文章说明,在这里不再重复描述。对于今天要说明的微服务治理管控我们假设如上图的场景,即:
有订单,用户和产品三个微服务暴露6个接口,其中3个属于内部使用走注册中心接入。另外三个接口注入接入到API网关,网关代理封装后暴露Http Rest接口提供外部小程序,App和CRM三个独立的应用访问。
在这个场景下三个微服务仅仅提供API接口注册,对于具体的API限流熔断都在API网关上面进行灵活的配置和管理,而这些配置和管控对微服务本身无任何侵入。
对于API网关本身也集群部署确保可靠性和性能,因此后续的限流熔断实际是基于整个集群入口总流量进行。其次,API网关的限流熔断,不仅仅是访问雪崩,包含后端的微服务模块,另外一个重要作用是保护API网关本身的性能和可靠性。
为了方便叙述,假设API网关接入并暴露了查询订单,查询用户,查询产品三个API接口服务。
对于限流熔断的基本实现思路可以先参考我前面文章:
限流,熔断和降级区别

先回顾下限流,熔断和降级具体的内容和区别。
对于限流简单来说就是入口流量控制,比如QPS超过了我们定义的某个基准值就禁止进入,当负荷下来后,又可以放入更多的请求。简单来说就是服务调用请求,超过了请求负荷就需要等待或被拒绝掉,但是等负荷下来你又可以调用通。
而熔断则是对整个API服务的处理,即整个API接口不再提供服务能力,直接拒绝访问。具体恢复可以手工恢复,也可以在我们设置的时间间隔后自动恢复。对于熔断一般则是根据并发量,错误数,响应时长等达到某个阈值,就直接触发熔断。
服务降级则是针对所有服务而不是单个服务的,即当出现巨大的访问量或并发量的时候,如何通过将非核心服务降级(限流或熔断)以释放资源,来保证核心服务SLA水平。
通过上面的解释总结如下:
限流时候本身不是服务完全不可用,而是对流量进行控制;而熔断则是完全服务不可用。服务降级不是针对单个服务,而是整个服务群,服务降级措施可以是限流,也可以是熔断。
服务限流
在前面已经谈到,在去中心化的微服务架构下,限流功能的实现仅仅是为了包含微服务本身不超负荷运转。我们还是以开在商场里面的餐馆的例子来进行说明。
即一个餐馆最多只能容纳100桌就餐,当全部满员后新来的人就需要等待,只有等已经在就餐的客人就餐完毕空出资源后才能够进入。但是这个时候餐厅本身的客流本身来源于两个点,一个是逛商城的人随机过来的,一个是餐厅的少量会员VIP客户。但是餐厅本身没有包间,也就是说当普通客户过多的时候直接导致餐厅排队,VIP客户并不能得到应有的服务。
这个时候我们希望的做法是对普通客户流量进行控制,而不是由于大量普通服务需求的满足导致了VIP客户排队或服务无法得到满足。即餐馆不仅需要考虑自身负荷,还需要考虑对不同类型客户的服务质量。
对应到微服务里面同样,即订单查询服务时间上有APP,小程序和CRM三个服务消费方。不能由于某一个消费方的大量调用而导致其它消费方服务请求也受影响。
即在这个场景下,实际上服务限流本身是两个层级的限流。
其一是对服务入口总流量进行限流,确保微服务本身在负荷之内;其二是对单个服务进行限流,以确保微服务本身有空余能力满足其它服务。
在实际当前开源的微服务限流熔断实现上,基本很难控制到单个应用请求方,而对应API网关在进行限流熔断实现的时候,我们则可以完全做到这点。
具体的并发量设置多少?
对应服务限流设置,我们以一秒内的QPS请求数阈值进行配置。那么针对一个微服务API接口,究竟应该配置多大的QPS值?对于这个问题仍然是事前和事后两种处理方式。
对于事前方式即我们在微服务上线前就要准备和模拟真正的业务场景,进行API接口的性能测试,看下API本身的性能和QPS数据。
我们可以不断地加大并发观察两个关键指标,一个是系统本身的资源负荷情况,一个是服务本身的响应时长情况。比如加大到500并发的时候,资源负荷已经超过80%,那么这个时候500并发就是极限值。但是你可能加大到300个并发的时候服务响应时长已经指数级增长而无法满足业务需求,那么这个时候你就只能取300并发下实际的QPS数据。
在配置的时候我们对QPS数据再预留点冗余即是我们可以配置的限流值。
当然也可以是后期处理方式,比如前期我们对限流没有任何配置,但是上线后会发现业务并发达到某个值的时候服务响应缓慢或者资源负荷很大导致内存泄漏等。那么这个时候,我们就需要基于实际服务运行采集到的值进行配置。
对于限流的思考
对于限流前面已经描述过,实际有两种情况,一个就是请求直接排队等待,连接保持;一种是请求访问直接被拒绝掉,但是过一会访问又可以访问了。
如果真要启用限流,建议采用第一种情况。任何一个接口服务对于消费方来说,如果出现一会可用,一会不可用,需要消费方自己不断地去重试都是不可接受的。虽然保证了微服务提供端的可靠性,但是对于服务提供本身的友好性则大打折扣。
即使是排队等待,我们也需要考虑连接超时配置,你要确保在连接超时前,排队等待的请求都能够被正常地处理掉。
举个高速入口收费站的例子说明。
当车辆进入收费站的时候,可以进行排队,但是约定的最大等待时间是10分钟。即我们进入排队后就需要在10分钟内能够通过,如果你无法满足这个约定,你可以在我排队前就告诉我收费站满负荷了,请走其它入口。
服务熔断
对于限流前面已经谈到,一般是根据并发和QPS数来设置限流,但是我们并不明确超过了设置的QPS值是否就一定把微服务压垮。
在前面也给出了一般需要根据访问时长和资源利用率来测算具体设置多少QPS合理。
而服务熔断除了前面谈到是将这个服务设置为不可用外,更加重要的就是服务熔断的规则设置除了并发数外,还可以设置类似服务响应时长,服务报文数据量等。
而服务响应时长慢,或者报文量增大往往才是导致整体微服务或API网关出现不可用并造成雪崩效应的关键。单个服务的熔断不仅仅是防止雪崩效应,更加重要的是防止单个服务大量的占用JVM内存资源,占用线程资源而导致了整体API网关出现内存溢出。

对于服务熔断,同样也存在上面的问题。
比如对于订单信息查询接口,你会发现仅仅是CRM系统出现了大并发量和大数据量的访问,由于CRM的大量访问导致了接口运行缓慢。这个时候不应该对整个接口进行熔断,而是应该仅仅对CRM系统的访问进行熔断。
即需要做到从服务粒度 =》(服务消费方 + 服务)粒度。
API网关和注册中心混合架构

在一个微服务架构环境下,由于内部的各个微服务之间可能走的是服务注册中心这种去中心化的模式,而仅仅需要对外暴露的接口服务注册到了API网关上面进行对外开放。
那么这个时候就可能同时存在内部微服务体系中的熔断和API网关上的熔断两处配置。但是这两处配置都是必须进行的。
对于内部的类似Hystrix熔断配置主要是针对内部的API接口访问和调用,重点是包含微服务模块本身可靠性;而对于API网关本身限流主要是针对外部访问,一方面是对大并发访问进行第一次拦截,一方面是保证API网关本身的稳定性不超负荷。
但是实际你会看到,在这种混合架构下如下一个新问题,即没有一个地方对所有的流量进行汇集而实现总的限流控制。
那么在这种情况下,采用熔断则是最好的方式。
因为熔断本身不是基于并发量,而是基于服务响应时间,报文量等进行熔断控制。但是在混合架构下如何形成统一的规则计算?这个时候就需要两个限流熔断控制点都访问统一个日志中心和规则计算中心。具体参考下图:

在这种模式下基本就可以实现一个整体的熔断管理。
服务降级

在这里先谈下微服务架构里面谈到的服务降级,在微服务架构下的降级一般会谈两种形式的降级,一种是屏蔽降级,一种是熔断降级。
对于屏蔽降级,简单来说就是在微服务多节点集群部署的情况下,当发往某一个集群节点,比如C节点的服务访问调用出现大量异常错误的时候,我们需要对C节点进行屏蔽。
对于熔断降级,则实际和熔断类似了,即当对于微服务的大并发访问导致服务性能下降的时候,我们需要对服务进行熔断。这和前面谈到的熔断基本一致。但是这里的熔断往往更加灵活,比如可以将熔断器全部打开,半打开或全部关闭等。

即在熔断后设置一个时间窗口恢复,在恢复的时候仅仅放入少量服务调用进行验证,如果服务已经恢复正常则将熔断器关闭,如果仍然访问失败则继续打开熔断器并顺延一个时间窗口。
而对于API网关来谈服务降级,即在API网关本身能力有限的情况下,如何确保高SLA的服务都能够得到需求满足,在出现大并发访问等场景的时候优先牺牲低SLA服务。
拿上面的场景来举例。
即不存在对于查询订单API接口并发量上来响应时间无法满足需求情况下对该接口降级的说法,这种情况只能叫对该接口限流。而实际场景说法应该是当查询订单API接口响应无法满足需求的时候,由于该接口是高SLA接口,因此需要对查询用户接口进行限流或熔断。以确保更多的资源能够分配给查询订单接口使用。
拿去银行办理业务的窗口来举例:
最初是4个普通窗口,一个VIP贵宾窗口。但是当天VIP用户来办理业务的人相对多,这个时候不能降低VIP用户的服务水平,因此需要将普通窗口减少到3个,而VIP窗口增加为2个。
我们可以再回顾下SLA服务等级协议,即:
SLA:Service-Level Agreement的缩写,意思是服务等级协议du。zhiSLA是关于网络服务供dao应商和客户间的一专份合同,其书中定义了服务类型、服务质量和客户付款等术语。按照 SLA 要求,服务供应商采用多种技术和解决方案去监控和管理网络性能及流量,以满足 SLP 中的相关需求,并产生对应的客户结果报告。
那么对于微服务下的API接口服务,同样存在SLA等级要求。我们在进行微服务接口定义和设计的时候需要对里面的关键要求进行定义。比如:
- 服务响应时间要求:<2S
- 服务高可用性要求:99.99%
这些就是关键的KPI指标,可以基于这些指标来进行服务SLA等级的划分。
基于监控预警来进行手工降级
在整个服务运行中,一般还有服务运行监控预警功能,即设置相关的服务KPI指标或组合指标,当这些指标阈值满足的时候就发出监控预警信息。
比如服务响应环境,JVM内存使用率居高不下等都可以进行预警,在出现预警后运维人员可以基于当前服务运行的真实情况来判断具体是哪个服务或哪个消费方导致的服务运行性能问题,并对相应的服务进行熔断操作。
如果是高SLA服务本身性能出现问题而整个集群资源负荷大的情况下,那么就需要对非核心业务涉及到的微服务或微服务API进行手工关闭或限流熔断。
智能化的服务限流和熔断处理
在这里从API网关进行接口服务集成和暴露的角度出发,是否需要对网关接入的每一个服务都进行相应的服务限流和熔断配置?
由于每个服务本身的并发量不一样,出现峰值的时候也不一样,同时API网关本身承载了多个服务实际更多需要的是控制整个API网关本身的性能负荷,确保网关运行的稳定性。
微服务架构体系下,对于微服务框架内本身也有熔断降级处理措施和机制,那么在这种场景下API网关的限流熔断首先要考虑为了自身的高可靠性运行需求。
如果我们对每个服务都进行配置,往往并不能很理想地达到限流熔断的目的。基于项目实际的实践情况来看,要么是这个值配置的太小,导致对本身可以通过的服务请求进行了熔断和拒绝;要么是这个值配置的太大,API网关本身已经内存溢出也没有触发熔断规则。
那么究竟是什么会影响到API网关的稳定性?
这个一方面是大量的服务访问请求连接长时间保持不释放,导致线程池被消耗完;一方面是出现大报文的消息调用,导致JVM持续增长而无法回收。这两种才是导致API网关出现宕机,重启或不可用的关键因素。
简单来说即首先设置一个统一的JVM阈值和线程池当前线程数阈值即可。
然后规则中心对两个值进行持续的心跳监控,当发现阈值超过的时候,快速地找到对应的接口服务和服务请求方,并执行限流或熔断操作,必要的时候还可以直接kill掉当前线程。如果上述方法还不能恢复的话,还需要对集群中超过阈值的节点强制进行节点重启操作,以防止集群进行故障漂移,导致正常节点也出现问题。
其次,整个服务性能下降也可能出现在月结或年结的时候,这个时候监控中心并不会发现有明显突发的大并发调用或大报文调用,而是所有接口服务访问量都线性在增长。这个时候一方面可以自动触发资源弹性扩容操作,另外一个方面就是可以实施服务降级策略,将SLA等级低的服务进行限流或者直接熔断以释放资源。
API网关限流熔断整体逻辑
对于整个限流熔断的处理逻辑流程,我们可以简化为下图:

对于该图,实际可以看到,如果按 Slot计算逻辑单元划分的思路可以分为:
- 基于配置的规则将服务运行实例按资源颗粒度匹配要求存到实例数据暂存区
- 进行第一次汇总计算
- 将汇总数据推入到滑动时间窗口数组
- 基于规则配置进行二次汇总计算
- 对限流熔断是否触发进行判断和处理
我们再将上面的思路做一个简单的描述。
比如我们当前在限流熔断规则配置中配置了三条独立的规则,不同的资源颗粒度。
- 规则1:对于CRM消费getCustomer接口进行限流,10分钟调用>1万即拒绝
- 规则2:对于getProductinfo接口流控,5分钟错误>1%则整体熔断
- 规则3:对于ERP系统提供所有服务,1分钟平均时长>30秒则整体熔断
如果是以上三条独立的限流熔断规则,则我们需要配置三个不同的临时数据存储区和三个独立的滑动时间窗口区。
在朝10秒临时数据暂存区推送临时数据的时候可能会造成冗余,但是在限流规则本身不带来配置的情况下该方案反而是最优方案。毕竟在实际应用场景中,我们往往是在发现了明细的性能异常或问题的时候才会配置限流熔断规则。
比如,CRM系统调用getCustomer API接口。
当获取到这次实例数据的时候,我们将其推送到第一个缓存集合,如果该接口本身也是ERP系统提供的接口,那么我们会同时将该数据推送一份到ERP系统缓存集合。
对于缓存数据集,我们每10秒就做一次汇总处理。并将汇总完成的结果数据形成一条记录推送到对应的滑动时间窗口区。在推送完成后将该数据集数据全部清空或进行资源释放。
基于滑动窗口数据的二次数据处理
对于滑动窗口中的二次数据处理,我们可以在每次数据推送完成后就计算一次滑动窗口数据,比如5分钟规则,我们就获取窗口中最近5分钟的数据进行二次汇总,并判断二次汇总后的数据是否满足了相应的触发条件。
如果满足条件,就进行限流熔断处理。
对于这部分内容的详细说明,可以参考我前面发布的文章: