Shardingjdbc启动优化,你学会了吗?
一.Sharding-JDBC 启动优化
问题分析
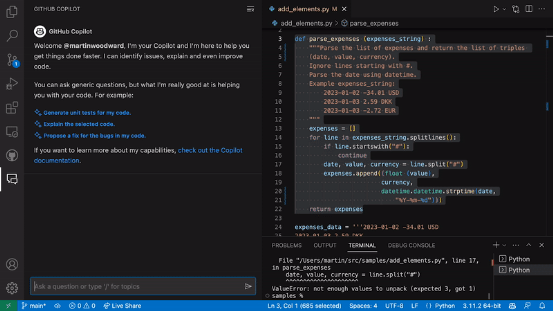
最近在本地调试的时候发现,项目本地启动比较慢,对启动日志进行分析,Sharding-JDBC 在加载元数据的过程中中耗时 116 秒 ,占用了项目启动时间的一半。
[org.Apache.shardingsphere.core.log.ConfigurationLogger:104] : [0||0] Properties:
max.connections.size.per.query: '1'
[org.apache.shardingsphere.core.metadata.ShardingMetaDataLoader:131] : [0||0] Loading 2 logic tables' meta data.
[org.apache.shardingsphere.sql.parser.binder.metadata.schema.SchemaMetaDataLoader:70] : [0||0] Loading 401 tables' meta data.
[org.apache.shardingsphere.shardingjdbc.jdbc.core.context.MultipleDataSourcesRuntimeContext:59] : [0||0] Meta data load finished, cost 115930 milliseconds.
分析加载流程,核心部分在 SchemaMetaDataLoader#load。
List<List<String>> tableGroups = Lists.partition(tableNames, Math.max(tableNames.size() / maxConnectionCount, 1));
Map<String, TableMetaData> tableMetaDataMap = 1 == tableGroups.size()
? load(dataSource.getConnection(), tableGroups.get(0), databaseType) : asyncLoad(dataSource, maxConnectionCount, tableNames, tableGroups, databaseType);
进入代码看一下,发现这里会根据 maxConnectionCount 对数据库的表分组进行不同的加载策略,往上游看一下这个 maxConnectionCount 来源于 Sharding-JDBC 的配置,默认为 1。
public enum ConfigurationPropertyKey implements TypedPropertyKey {
//.......
/**
* Max opened connection size for each query.
*/
MAX_CONNECTIONS_SIZE_PER_QUERY("max.connections.size.per.query", String.valueOf(1), int.class)
//......
}
那是不是把这个配置扩展一下就可以提高启动速度了?在将配置随意设置成 8 之后由 116s 提升至 15s。
从这里来看启动问题解决了,同时也产生了疑问,为什么 max.connections.size.per.query 默认值设置为 1。
这里是官网对于配置的解释,物理数据库为每次查询分配的最大连接数量。

光看字面意思无法评估影响面,那就从 Sharding-JDBC 的查询入口开始看一下 ShardingPreparedStatement#executeQuery
public ResultSet executeQuery() throws SQLException {
ResultSet result;
try {
clearPrevious();
prepare();
initPreparedStatementExecutor();
MergedResult mergedResult = mergeQuery(preparedStatementExecutor.executeQuery());
result = new ShardingResultSet(preparedStatementExecutor.getResultSets(), mergedResult, this, executionContext);
} finally {
clearBatch();
}
currentResultSet = result;
return result;
}
......
SQLExecutePrepareTemplate#getSQLExecuteGroups
private List<InputGroup<StatementExecuteUnit>> getSQLExecuteGroups(
final String dataSourceName,
final List<SQLUnit> sqlUnits,
final SQLExecutePrepareCallback callback) throws SQLException {
List<InputGroup<StatementExecuteUnit>> result = new LinkedList<>();
int desiredPartitionSize = Math.max(0 == sqlUnits.size() % maxConnectionsSizePerQuery ? sqlUnits.size() / maxConnectionsSizePerQuery : sqlUnits.size() / maxConnectionsSizePerQuery + 1, 1);
List<List<SQLUnit>> sqlUnitPartitions = Lists.partition(sqlUnits, desiredPartitionSize);
ConnectionMode connectionMode = maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY;
List<Connection> connections = callback.getConnections(connectionMode, dataSourceName, sqlUnitPartitions.size());
int count = 0;
for (List<SQLUnit> each : sqlUnitPartitions) {
result.add(getSQLExecuteGroup(connectionMode, connections.get(count++), dataSourceName, each, callback));
}
return result;
}
这里可以看到,根据 maxConnectionsSizePerQuery 选择了不同的模式 CONNECTION_STRICTLY 、 MEMORY_STRICTLY
这里先说一下 sqlUnits 是什么,在分表之后进行查询,如果查询参数中不带分片参数的话,Sharding-JDBC 会将 SQL 进行处理,例复制
select * from table where field= “测试查询”;
实际执行的过程中会被处理成
select * from table0 where field = “测试查询”;
select * from table1 where field = “测试查询”;
select * from table2 where field = “测试查询”;
......
select * from table(n-1) where field = “测试查询”;
Sharding-JDBC 会将真实 SQL 查询的数据进行聚合,聚合的方式根据 maxConnectionsSizePerQuery 配置有两种,即 CONNECTION_STRICTLY、MEMORY_STRICTLY。
CONNECTION_STRICTLY 可以理解为对同一数据源最多创建 maxConnectionsSizePerQuery 个连接。
MEMORY_STRICTLY 则是对一次操作的数据库连接不做限制,同一数据源 n 张分表就创建 n 个连接,多线程并发处理。
从理论上看,是不是可以将 max.connections.size.per.query 设置的大一点,只要单次操作创建的数据源不超过数据库连接上限就可以了?其实不一定,这里进入 UPDATE 的方法看一下。
public int executeUpdate() throws SQLException {
try {
clearPrevious();
prepare();
initPreparedStatementExecutor();
return preparedStatementExecutor.executeUpdate();
} finally {
clearBatch();
}
}
发现这里在执行 SQL 前同 SELECT 执行了一样的预处理逻辑 initPreparedStatementExecutor() ,那么在 max.connections.size.per.query > 1 的情况下,无论是那种模式都可能会根据配置的不同获取多个数据源,执行 UPDATE 就有可能存在死锁问题。
例:
@Transactional
public void test(){
updateByID(1);
updateByKey(1);
}
 图片
图片
所以最终得出结论目前状态下,测试环境、预发环境可对max.connections.size.per.query 进行配置,提高启动速度,在线上环境 max.connections.size.per.query 默认为 1 保证应用的稳定。
总结
在分析启动问题的过程中对 Sharding-JDBC 查询过程进行了简单的了解,规避了线上可能引发的问题,同时也提醒了自己在改动一些配置时需要对配置所涉及的影响面进行充分评估后再进行改动。
参考资料
- Sharding-JDBC 官方文档 https://shardingsphere.apache.org/document/current/cn/overview/